最近开始学习斯坦福大学Andrew Ng的机器学习课程,感觉受益匪浅,今天就让我们一同初探机器学习的大门,走进神奇的机器学习世界!
生活中的机器学习
你觉得机器学习离我们很远吗?其实不然,在生活中,每天我们都可能在不知不觉中使用了各种各样的机器学习算法。比如,当你每一次使用像诸如谷歌 (Google)或必应 (Bing) 的搜索引擎时,它们运作得如此之好的原因之一便是由Google或微软实现的一种学习算法可以“学会”如何对网页进行排名;每当你使用脸书 (Facebook)或苹果 (Apple) 的照片处理应用时,它们都能自动识别出你朋友的照片,这也是机器学习的一种;每当你阅读电子邮件时,你的垃圾邮件过滤器帮你免受大量垃圾邮件的困扰,这同样也是通过一种学习算法实现的。
话说为什么机器学习在当今如此流行呢?机器学习发源于人工智能领域,我们希望能够创造出具有智慧的机器,比如能找到从A到B的最短路径。但在大多数情况下,我们并不知道如何显式地编写人工智能程序来做一些更有趣的任务,比如网页搜索、标记照片和拦截垃圾邮件等。人们意识到唯一能够达成这些目标的方法就是让机器自己学会如何去做,因而 机器学习已经发展成为计算机的一项新能力,并且与工业界和基础科学界有着紧密的联系。
在硅谷机器学习引导着大量的课题,如自主机器人、计算生物学等。机器学习的实例还有很多,比如数据库挖掘之类的。机器学习变得如此流行的原因之一便是网络和自动化算法的爆炸性增长,这意味着我们掌握了比以往多得多的数据集。举例来说,当今有数不胜数的硅谷企业在收集有关网络点击的数据 (Clickstream Data) 并试图在这些数据上运用机器学习的算法来更好的理解和服务用户。这在硅谷已经成为了一项巨大的产业。随着电子自动化的发展,我们现在拥有了电子医疗记录,如果我们能够将这些记录转变为医学知识,那我们就能对各种疾病了解的更深入。同时计算生物学也在电子自动化的辅助下快速发展,生物学家收集了大量有关基因序列以及DNA序列的数据,通过对其应用机器学习的算法来帮助我们跟深入地理解人类基因组及其对我们人类的各种疾病。
几乎工程界的所有领域都在使用机器学习算法来分析日益增长的海量数据集,有些机器应用我们并不能够通过手工编程来实现。比如说想要写出一个能让直升机自主飞行的程序几乎是不可能的任务,唯一可行的解决方案就是让一台计算机能够自主地学会如何让直升机飞行;再比如手写识别,如今将大量的邮件按地址分类寄送到全美甚至全球的代价大大降低,其中重要的理由之一便是每当你写下这样一封信时,一个机器学习的算法已经学会如何读懂你的笔迹并自动地将你的信件发往它的目的地,所以邮寄跨越上万里的信件的费用也很低。
你也许曾经接触过自然语言处理和计算机视觉,事实上这些领域都是试图通过人工智能来理解人类的语言和图像。如今大多数的自然语言处理和计算机视觉都是对机器学习的一种应用。机器学习算法也在用户自定制化程序(self-customizing program)中有着广泛的应用。每当你使用亚马逊 Netflix或iTunes Genius的服务时,都会收到它们为你量身推荐的电影或产品,这就是通过学习算法来实现的。 可以相信这些应用都有着上千万的用户,而针对这些海量的用户编写千万个不同的程序显然是不可能的,唯一有效的解决方案就是开发出能够自我学习,定制出符合你喜好的并据此进行推荐的软件。最后 机器学习算法已经被应用于探究人类的学习方式,并试图理解人类的大脑,我们也将会了解到研究者是如何运用机器学习的工具来一步步实现人工智能的梦想。
所以其实机器学习离我们并不远,它渗透在我们生活的方方面面,使用机器学习将成为我们日后工作科研的一个重要组成部分,所以接下来就让我们一同了解一下机器学习中的一些重要概念吧!
什么是机器学习
机器学习是什么?实际上,即使是在机器学习的专业人士中,也不存在一个被广泛认可的定义来准确定义机器学习是什么或不是什么,现在我们将一同了解一些人们尝试定义的示例。
第一个机器学习的定义来自于Arthur Samuel。他定义机器学习为:在进行特定编程的情况下,给予计算机学习能力的领域。Samuel的定义 可以回溯到50年代,他编写了一个西洋棋程序。这程序神奇之处在于,编程者自己并不是个下棋高手。 但因为他太菜了,于是就通过编程,让西洋棋程序自己跟自己下了上万盘棋。通过观察哪种布局(棋盘位置)会赢,哪种布局会输,久而久之,这西洋棋程序明白了什么是好的布局, 什么样是坏的布局。然后程序通过学习后,玩西洋棋的水平超过了Samuel。这绝对是令人注目的成果。 尽管编写者自己是个菜鸟,但因为计算机有着足够的耐心,去下上万盘的棋。通过这些练习, 计算机获得无比丰富的经验,于是渐渐成为了比Samuel更厉害的西洋棋手。
上述是个有点不正式的定义,也比较古老。另一个年代近一点的定义,由Tom Mitchell提出,他来自卡内基梅隆大学。Tom定义的机器学习是:一个好的学习问题定义如下,一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理 T时的性能有所提升。这句话多少有些绕口,让我们来看看具体的例子,在西洋棋那例子中,经验E就是程序上万次的自我练习的经验,而任务T就是下棋。性能度量值P呢,就是它在与一些新的对手比赛时,赢得比赛的概率。
目前存在几种不同类型的学习算法。主要的两种类型被我们称之为监督学习和无监督学习。接下来我们会详细学习这些术语的定义。这里先简单说两句,监督学习这个想法是指,我们将教计算机如何去完成任务,而在无监督学习中,我们打算让它自己进行学习。此外你将听到诸如,强化学习和推荐系统等各种术语,这些都是机器学习算法的一员,以后我们都将介绍到。但学习算法最常用两个类型就是监督学习、无监督学习,我会在接下来的板块中给出它们的定义。
监督学习
现在,我将给你介绍一种也许是最常见的机器学习问题,即监督学习。我们现在现在先以示例来说明什么是监督学习,之后再给出正式的定义。假设你想预测房价且某学生已经从某地收集了数据集,其中一个数据集是这样的:
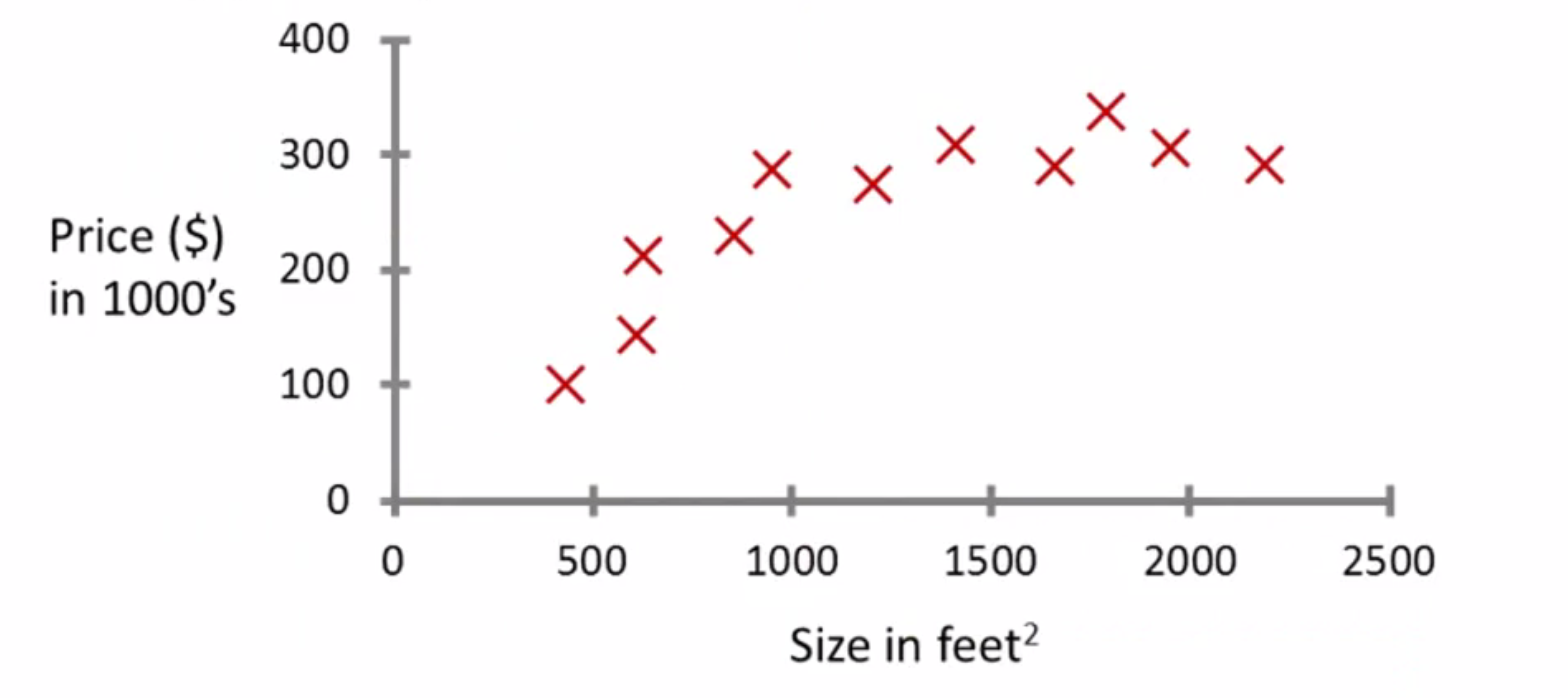
横坐标是不同房子的面积,单位是平方米; 纵轴上是房价,单位为千美元。 根据给定数据,假设你朋友有栋房子,750平尺(大约70平米) 想知道这房子能卖多少。 那么机器学习算法怎么帮你呢?
第一种方法,学习算法可以绘出一条直线,让直线尽可能匹配到所有数据。:
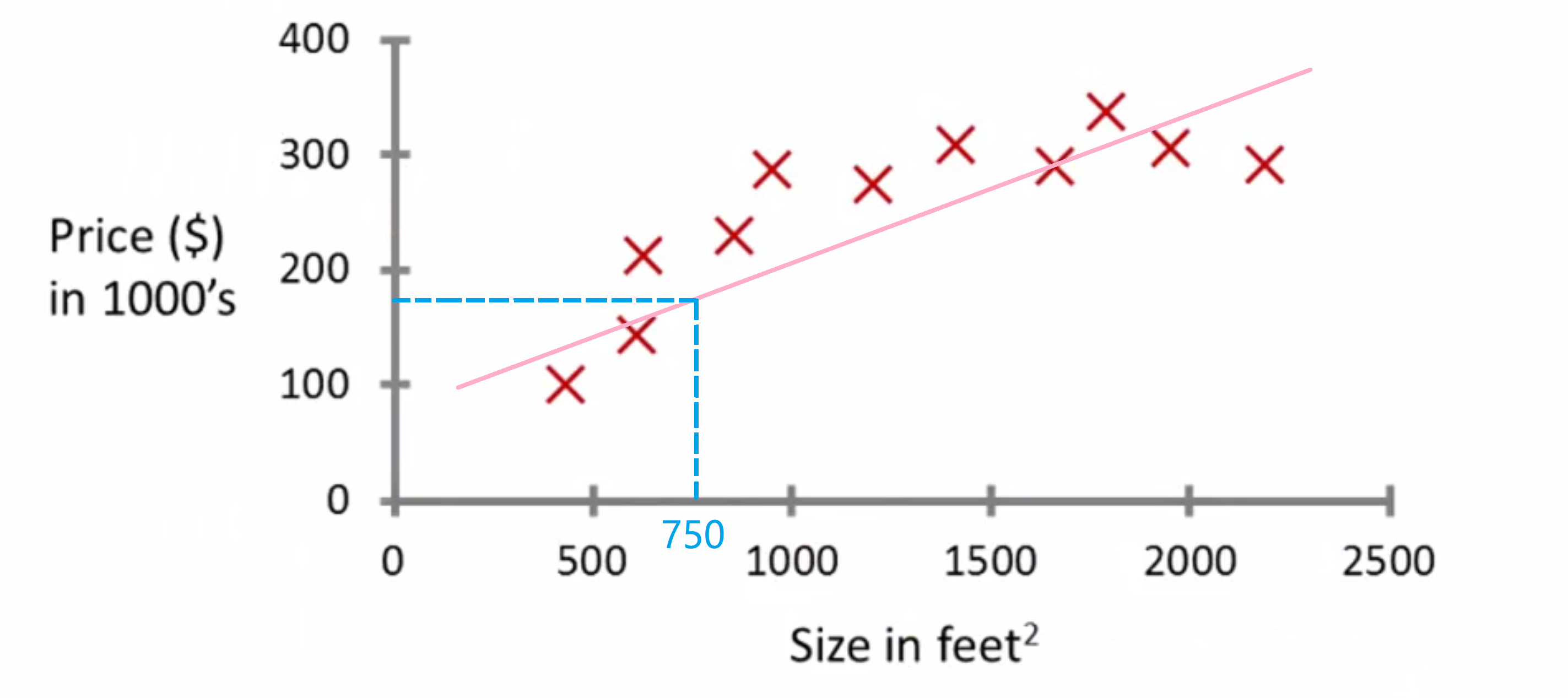
基于此,看上去,那个房子应该、可能、也许、大概 卖到18万美元。但这不是唯一的学习算法。 可能还有更好的。比如不用直线了, 可能平方函数会更好, 即二次多项式也许更符合数据集:
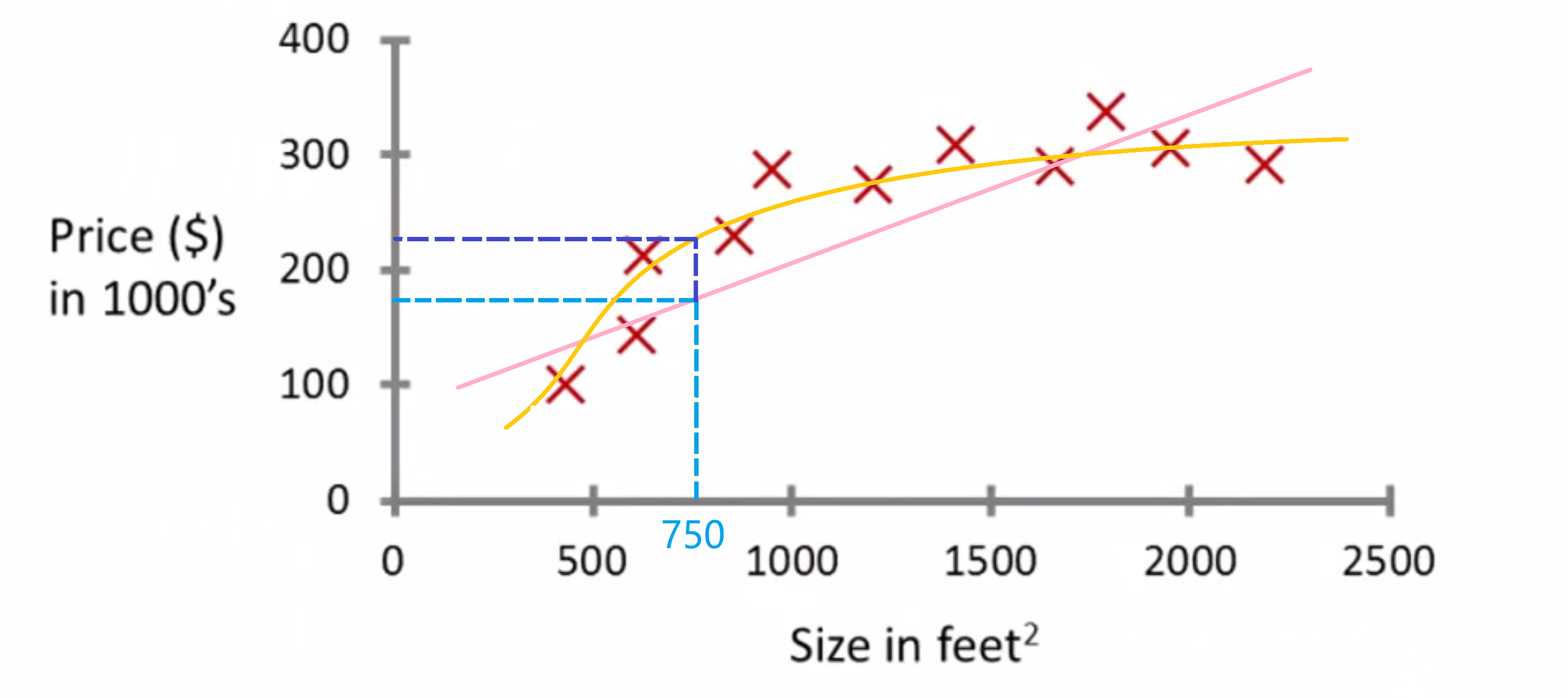
如果你这样做,预测结果就应该是22万刀。之后我们会介绍到如何选择适合的函数来拟合。如果没有明智的选择,就无法给你的朋友更好的卖房建议。
其实监督学习,意指给出一个算法,需要部分数据集已经有正确答案。比如给定房价数据集,对于里面每个数据,算法都知道对应的正确房价,即这房子实际卖出的价格。算法的结果就是算出更多的正确价格,比如那个你朋友想卖的那个新房子。在卖房问题上,更具体的,应该属于回归问题。回归问题属于监督中的一种,意指要预测一个连续值的输出,比如房价。 虽然从技术上,一般把房价记到美分单位尽管精度不低,但实际上还是个离散值,但是我们通常把它看作实际数字,是一个标量值,一个连续值的数,而术语回归, 意味着要预测这类连续值属性的种类。
另一个监督学习的例子,是通过医院的医学记录,预测胸部肿瘤是恶性良性:
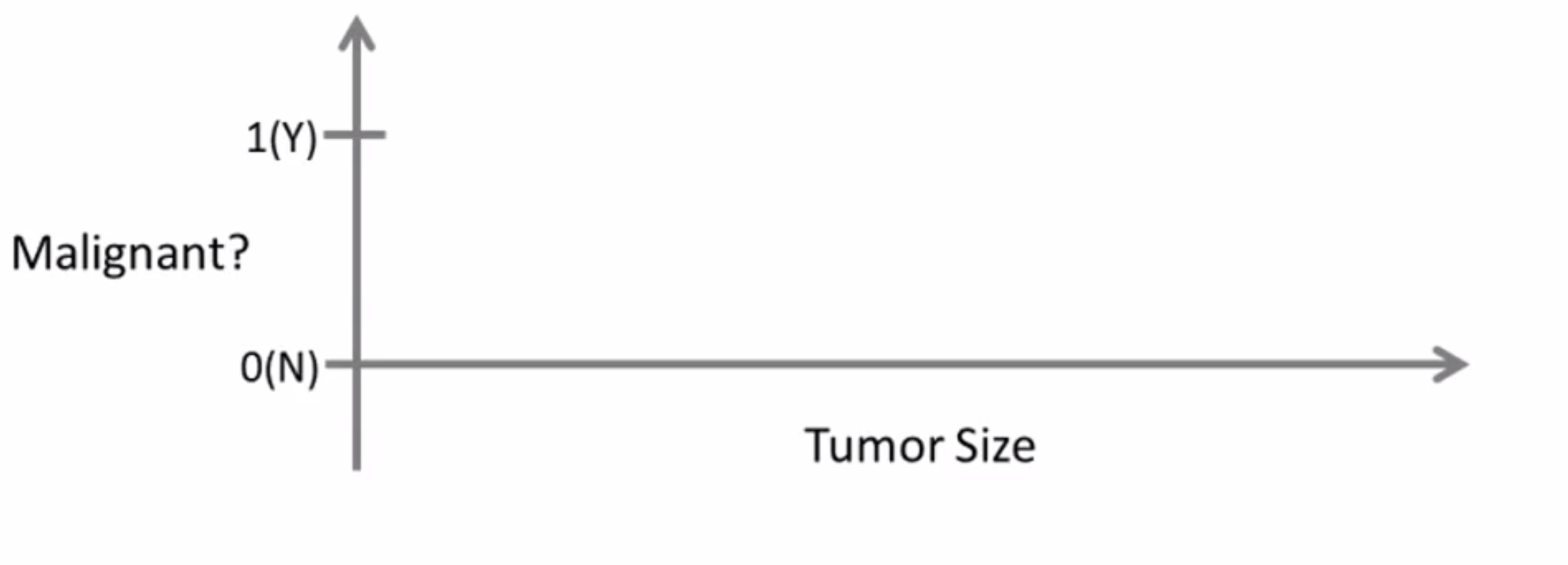
让我们看一个收集好的数据集, 假设在数据集中,横轴表示肿瘤的大小, 纵轴圈上0或1,是或否, 即肿瘤是恶性的还是良性的:
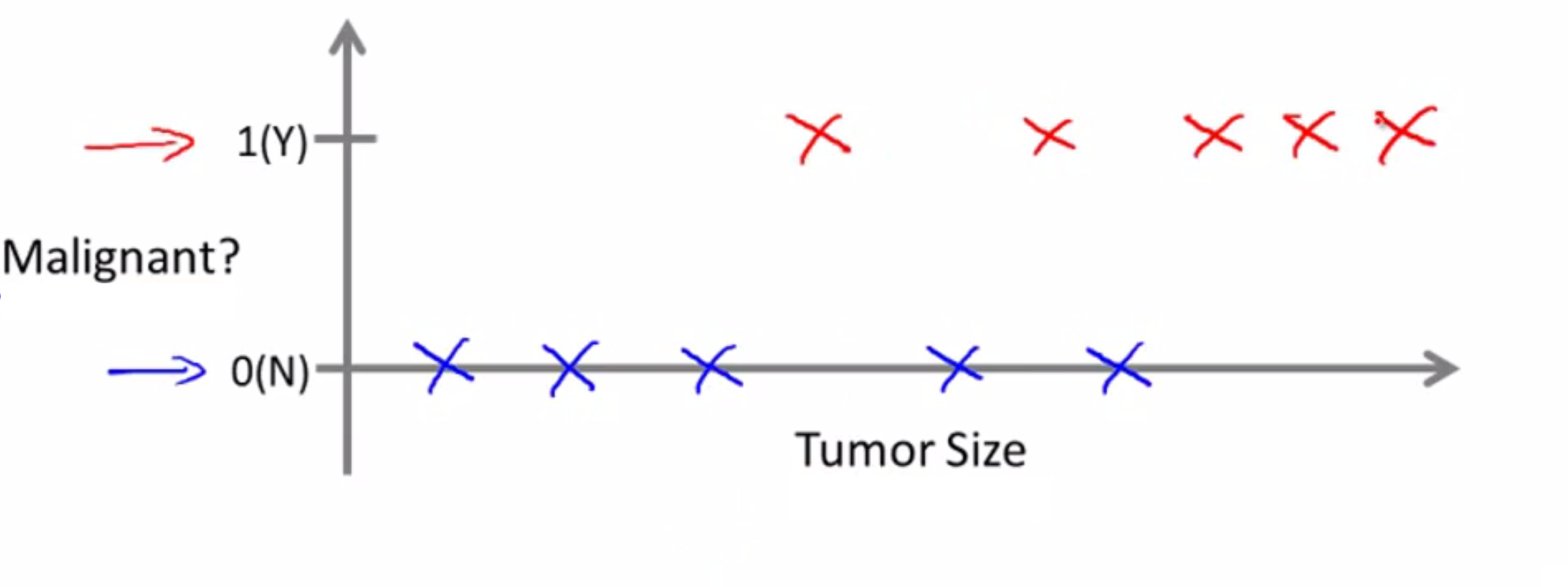
现在假设某人不幸地得胸部肿瘤了, 大小如紫色箭头所标注:
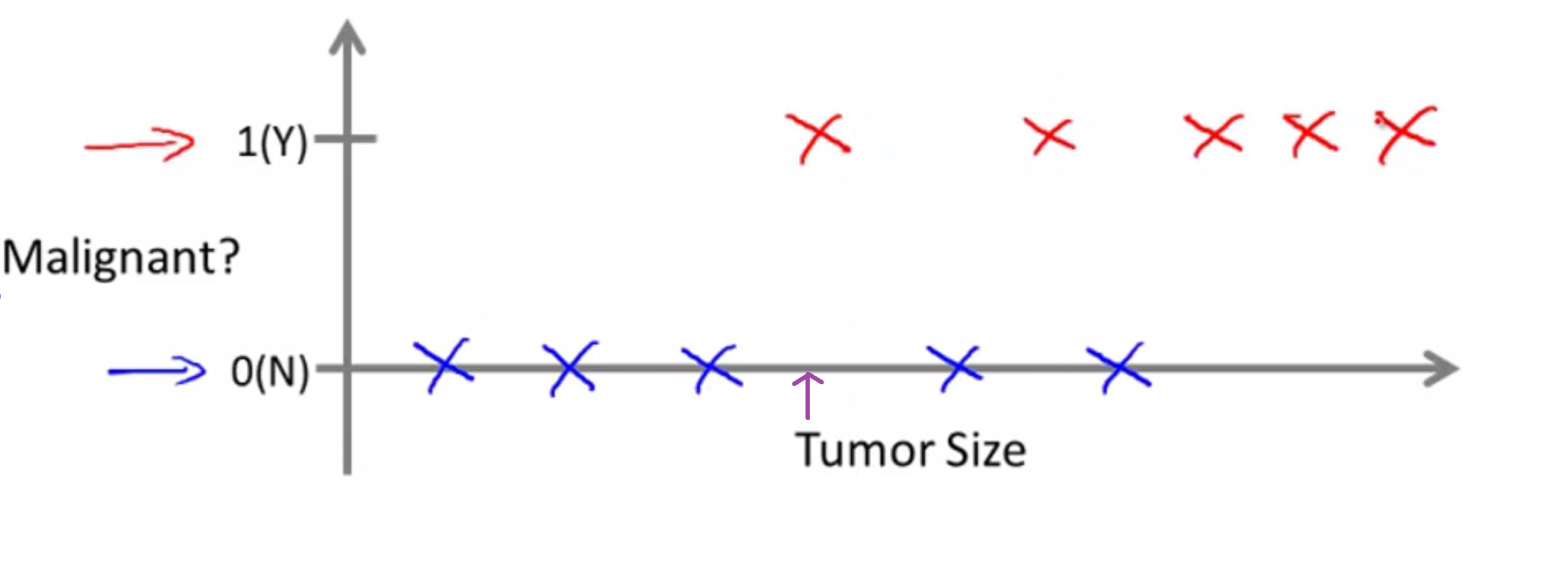
对应的机器学习问题就是,我们能否估算出一个概率, 即肿瘤为恶或为良的概率?
专业地说,这是个分类问题。 分类是要预测一个离散值输出。 这里是0或1,恶性或良性。事实证明, 在分类问题中,我们的数据有时会有超过两个的值,输出的值可能超过两种。举个具体例子, 胸部肿瘤可能有三种类型,我们设其为离散值0,1,2,3。假设总共有三种癌症,0就是良性肿瘤,没有癌症。 1 表示1号癌症, 2 是2号癌症,3 就是3号癌症。 这同样是个分类问题,因为它的输出的离散值集合,分别对应于无癌,1号,2号,3号癌症。
在分类问题中,还有另一种作图方式来描述数据。如果我们把肿瘤大小作为唯一属性, 被用于预测恶性良性,可以把数据作图成这样:

我们使用不同的符号来表示良性和恶性,即阴性和阳性。其实两者的联系就是,后者的作图方式其实就把在上面的数据映射下来,再用不同的符号,比如圈和叉来分别代表良性和恶性。
在上例中,我们只使用了一个特征属性,即肿瘤块大小, 来预测肿瘤是恶性良性。在其它机器学习问题里, 有着不只一个的特征和属性。例如,现在不只是知道肿瘤大小, 病人年龄和肿瘤大小都知道了。这种情况下, 数据集如下所示:
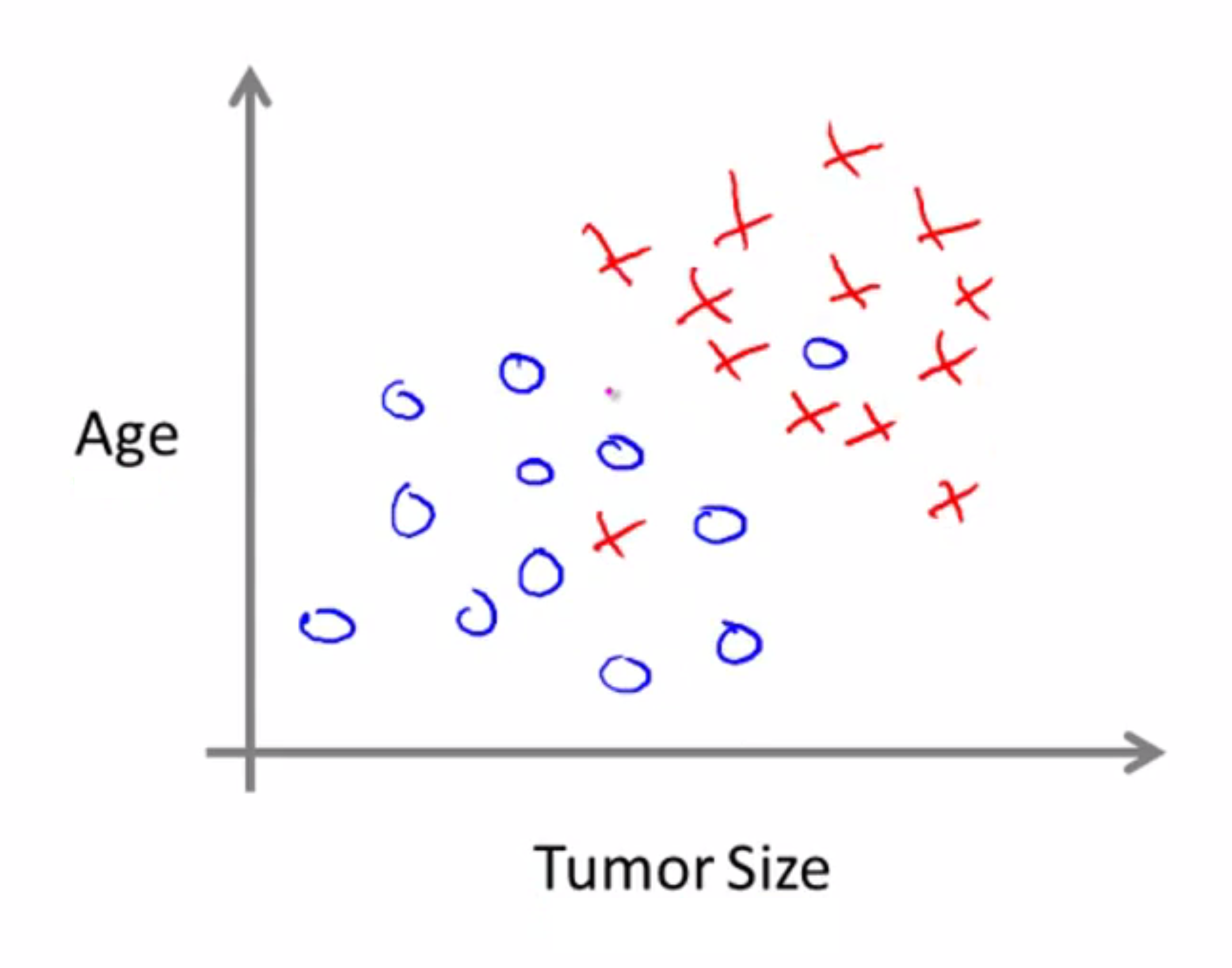
同样的我们还是把恶性肿瘤用叉来代表。所以假设有一朋友得了肿瘤。肿瘤大小和年龄都如下:
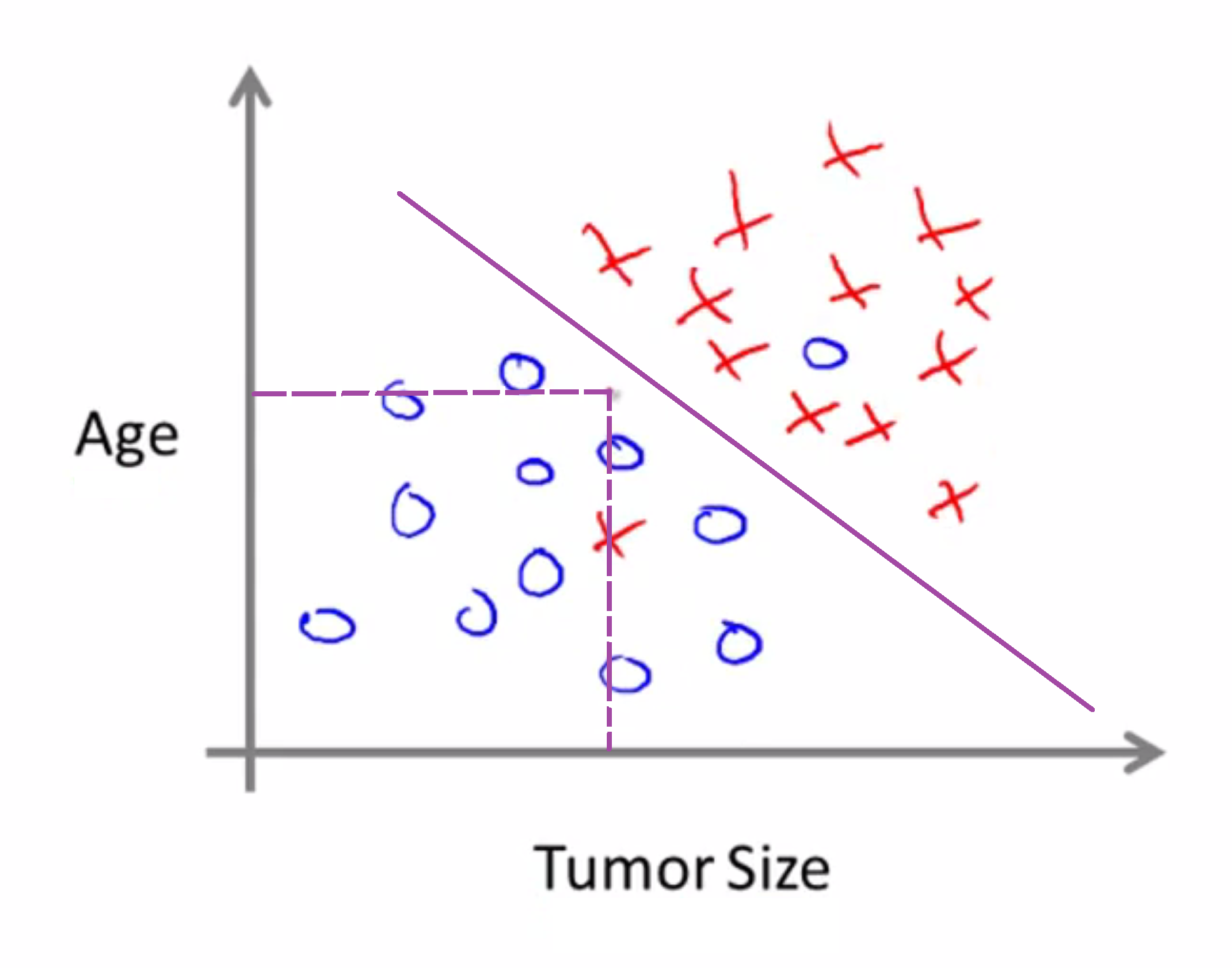
那么依据这个给定的数据集,学习算法所做的就是画一条直线,分开恶性肿瘤和良性肿瘤,然后学习算法就说 你朋友的肿瘤在良性一边,因此更可能是良性的。
在上一个例子中,总共有两个特征, 即病人年龄和肿瘤大小。在别的机器学习问题中, 经常会用到更多特征,比如在肿瘤研究上可能还用到块的厚度、肿瘤细胞大小和形状的一致性等等。
它表明,出色的学习算法应该能够处理无穷多个特征。不是3到5个这么少。 因为对于一些学习问题, 我们用到的不只是三五个特征,也许要用到无数多个特征。 所以,我们的学习算法要使用很多的属性或特征、线索来进行预测。那么,我们如何处理无限多特征呢?我们如何存储无数的东西 进电脑里,又要避免内存不足?事实上,之后我们会学习一种叫支持向量机的算法, 这是一种简洁的数学方法,能让电脑处理无限多的特征。之后我们会一同学习。
讲了这么多,让我们回顾一下,其实监督学习的基本思想是,对于数据集中的每个数据, 都有相应的正确答案,其算法就是基于这些数据集来做出预测。而监督学习主要又包括回归问题和分类问题两大块。
无监督学习
和之前一样,我们先举出关于无监督学习的例子,再进行具体的定义。在之前监督学习的数据集中,每个样本都已经被标明为正样本或者负样本,即肿瘤那个例子中的良性或恶性肿瘤。因此对于监督学习中的每一个样本,我们已经被清楚地告知了什么是所谓的正确答案,即它们是良性还是恶性:
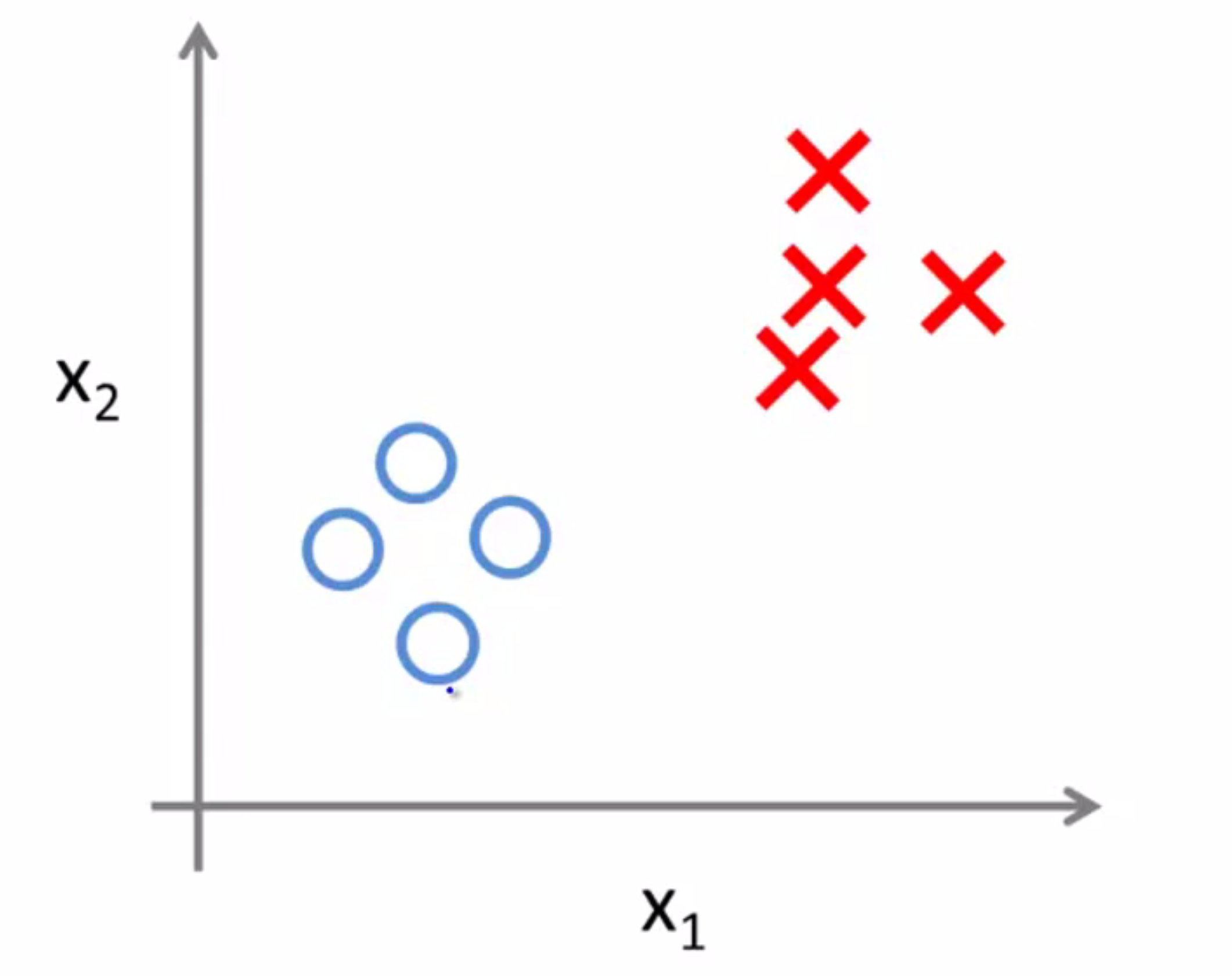
但在无监督学习中,我们所用到的数据集会和监督学习里的看起来有些不一样。在无监督学习中没有属性或标签这一概念,也就是说所有的数据的本质都是一样的,没有区别的,没人告诉我们该怎么做,我们也不知道每个数据点究竟是什么意思。它只告诉我们,现在这里有一个数据集,你能在其中找到某种结构吗?
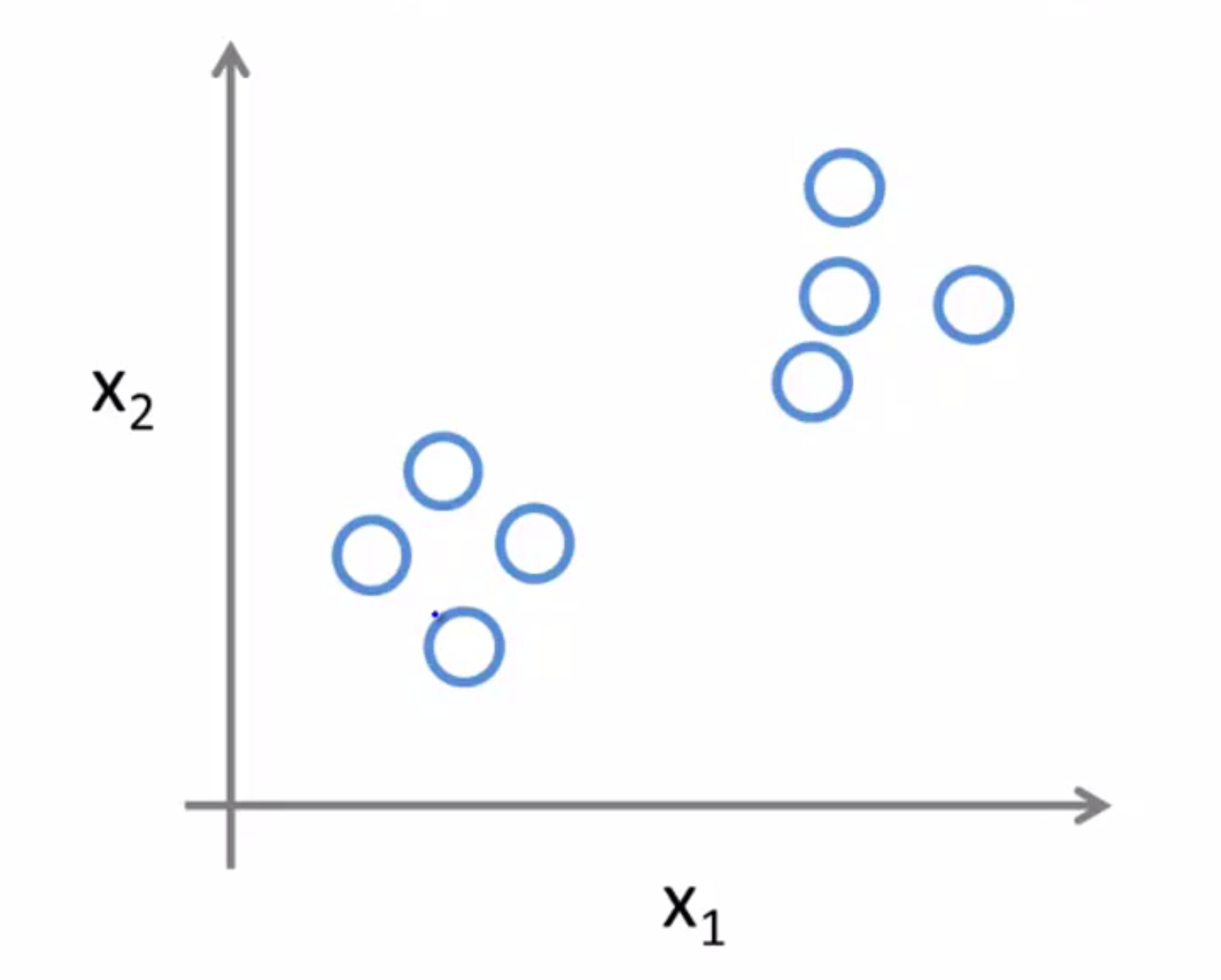
对于给定的数据集,无监督学习算法可能判定该数据集包含两个不同的聚类,所以这就是所谓的聚类算法:
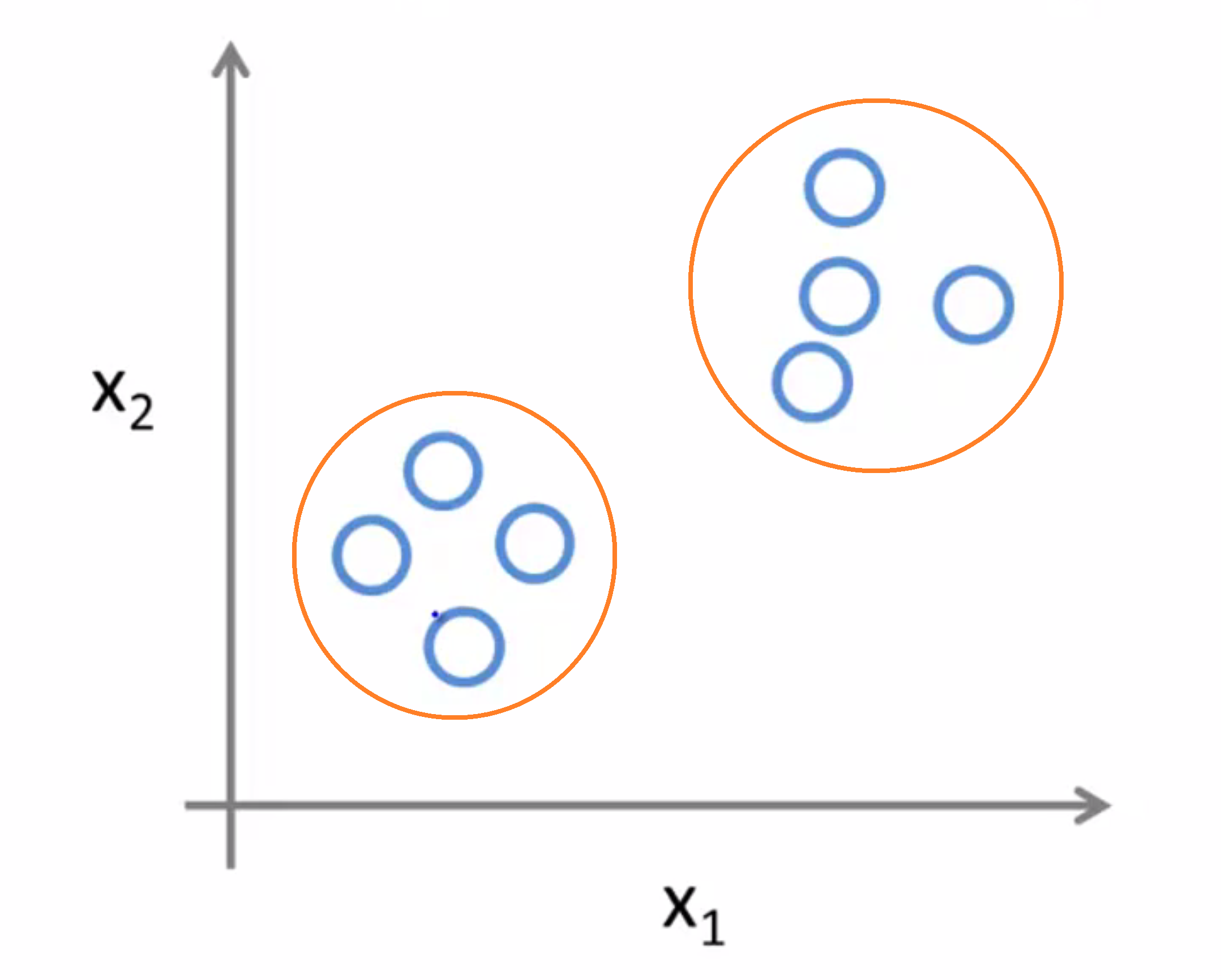
实际上它被用在许多地方,我们来举一个聚类算法的栗子: 比如在Google 新闻中,他们每天会去收集成千上万的 网络上的新闻,然后将他们分组,组成一个个新闻专题:
实际上,聚类算法和无监督学习算法也可以被用于许多其他的问题。这里我们举个它在基因组学中的应用,下面是一个关于基因芯片的例子:
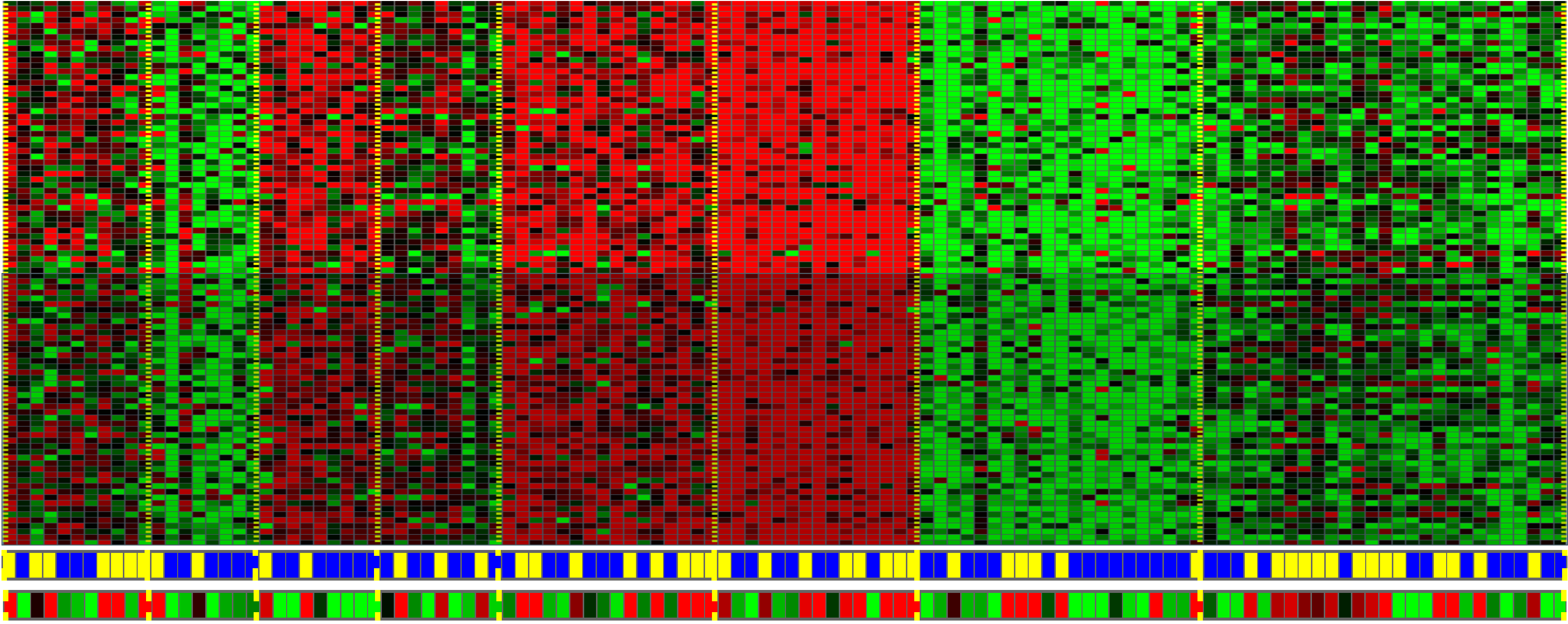
其想要达到的目的是,给定一组不同的个体,对于每个个体,检测它们是否拥有某个特定的基因。也就是说,你要去分析有多少基因显现出来了,其中的红绿灰等颜色展示了这些不同的个体是否拥有一个特定基因的不同程度。然后你能做的就是创造一个聚类算法,把不同的个体归入不同的类,这就是无监督学习。我们没有提前告知算法什么是第一类的,什么是第二类的,什么是第三类的等等,相反我们只是告诉算法:“你看,这儿有一堆数据,我不知道这个数据是什么东东,叫什么名字 我甚至不知道都有哪些类型,但是 请问你可以自动的找到这些数据中的类型吗?”然后程序就会自动地按可能的类型把这些个体分类:
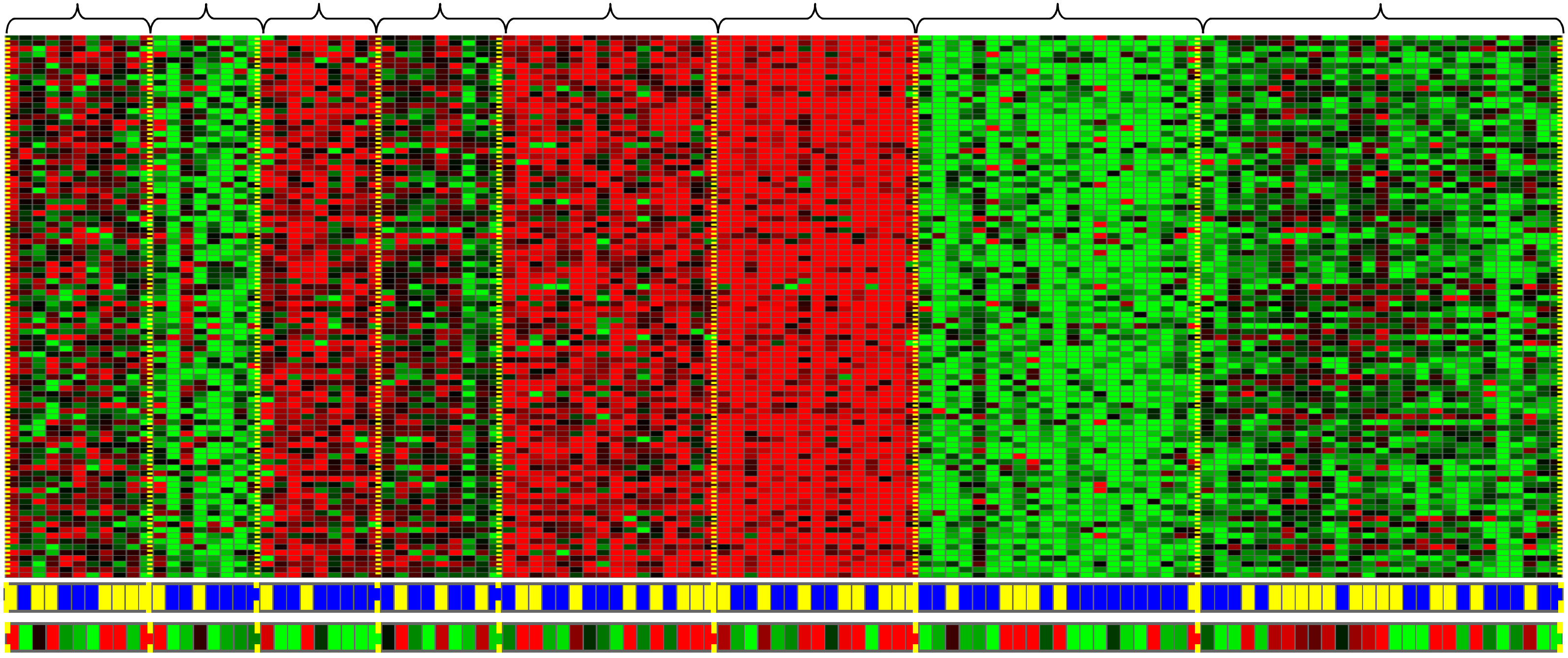
无监督学习或聚类算法在其他领域也有着大量的应用,它被用来组织大型的计算机集群,用来做社交网络的分析,用来做用户精准的市场分割,而在天文数据分析中,通过这些聚类算法,我们也同样发现了许多有趣的关于星系是如何诞生的理论。所有这些都是聚类算法的例子,而聚类只是无监督学习的一种,现在让我们来看另一种。
我先来介绍一下鸡尾酒宴问题,我想你应该参加过鸡尾酒会对吧?想象一下,有一个宴会,有一屋子的人,大家都坐在一起,而且在同时说话,有许多声音混杂在一起,因为每个人都是在同一时间说话的,在这种情况下你很难听清楚你面前的人说的话。因此,假如有这样一个场景,宴会上只有两个人,我们准备好了两个麦克风 把它们放在房间里 然后 因为这两个麦克风距离这两个人的距离是不同的,所以每个麦克风都记录下了来自两个人的声音的大小也是不同的。也许A的声音在第一个麦克风里的声音会响一点,也许B的声音 在第二个麦克风里会比较响一些,但每个麦克风都会录到来自两个说话者的重叠部分的声音:
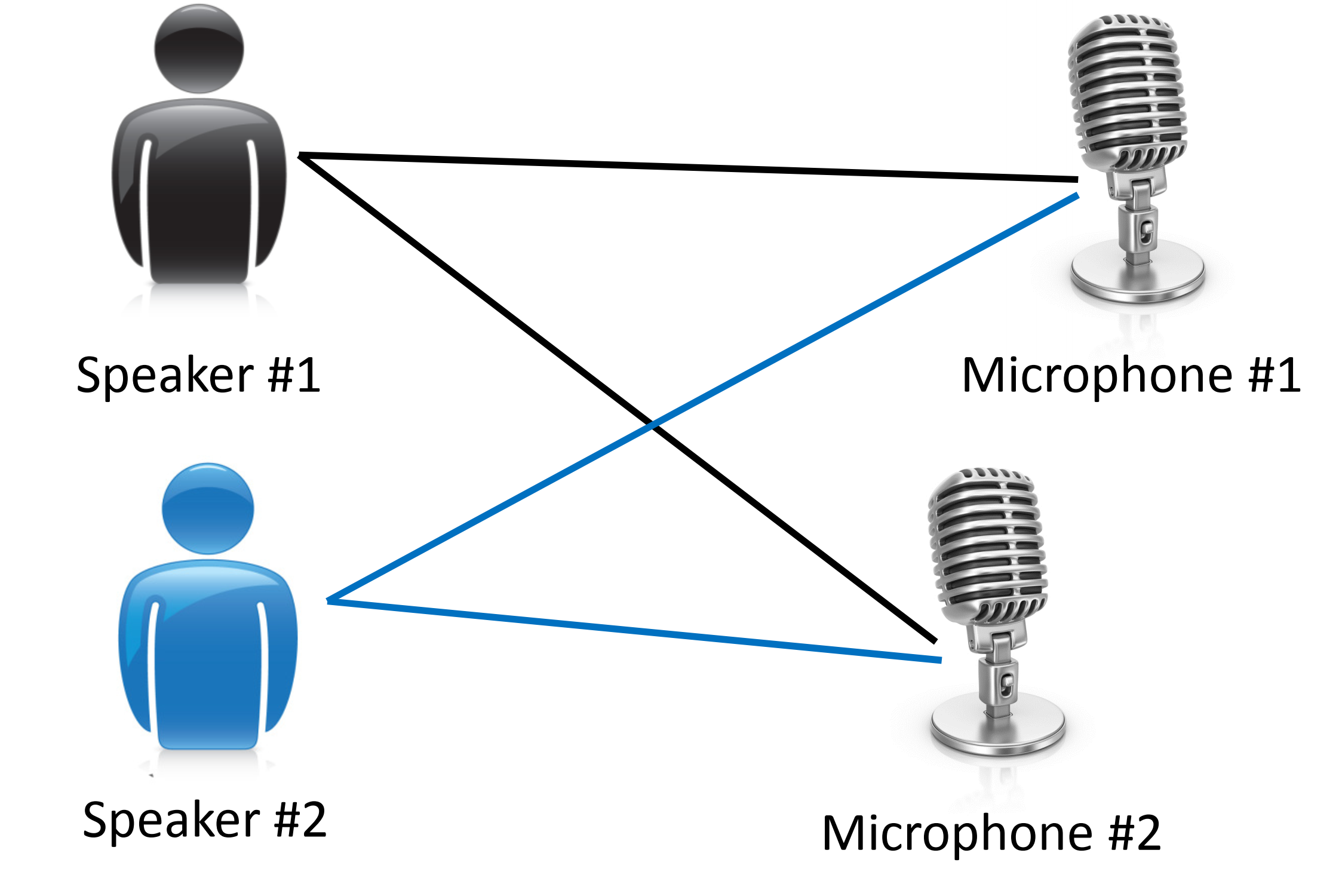
其中我们想做的就是把这两个录音输入,运用一种无监督学习算法——称为“鸡尾酒会算法” ,让这个算法帮我们找出其中蕴含的分类。然后这个算法会分析我们的录音,分离出 这两个被叠加到一起的音频源,即剥离出两个人单独的声音。也许你想 要实现这样的算法很复杂吧?确实看起来为了构建这个应用程序,做这个音频处理,似乎需要写好多代码啊,或者还需要链接到一堆处理音频的Java库,貌似需要一个非常复杂的程序分离出音频等。实际上要实现分离音频源的效果,只需要Octave中的一行代码就可以了:
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
SVD 意思是奇异值分解,但这其实是解线性方程组,但它被内置在Octave软件中了。如果我们试图 在C + +或Java中做这个,将需要写挺多行的代码,并且还要连接复杂的C + +或Java库。所以事实上在硅谷,很多人会这样做——他们会先用Octave来实现这样一个学习算法原型,只有在确定 这个算法可以工作后,才开始迁移到 C++ Java或其它编译环境。事实证明这样做来实现的算法,比一开始就用C++ 实现的算法要快多了。所以这里强烈安利各位同学抽空了解一下Octave语言。
综上,其实无监督学习的基本思想是,对于数据集中的每个数据, 我们并没有相应的正确答案,其算法的目的是对于给定的数据集,找到某种联系将数据分类,也是机器学习中一种重要的算法。
结语
在这篇BLOG中,我们初步了解了机器学习的一些定义和其中重要的监督学习和非监督学习,之后,我们还会继续一同学习一些主要算法的具体实现。最后希望你喜欢这篇BLOG!

