在之前的BLOG里,我们一同学习了异常检测系统开发的诸多细节,但是由于我们是对于各个特征分开处理概率的,导致了一些新的问题的产生。这篇BLOG,我们就来看看这些问题,以及学习如何使用多元高斯分布下的异常检测算法进行解决。
原算法的缺陷
对于我们之前学习的异常检测算法,一种可能的延伸多是进一步使用元高斯分布 (multivariate Gaussian distribution),相比较于普通的异常检测算法,它有一些优势也有一些劣势,它能捕捉到一些之前的算法检测不出来的异常,但是作为代价其运算效率会比较低下。
为了深入理解这个算法,让我们先来看一个例子。我们使用数据中心的监控机的例子,假设我们的没有标签的数据看起来像下面这张图一样,我们的两个特征变量 x1 是 CPU 的负和 x2 是内存使用量:
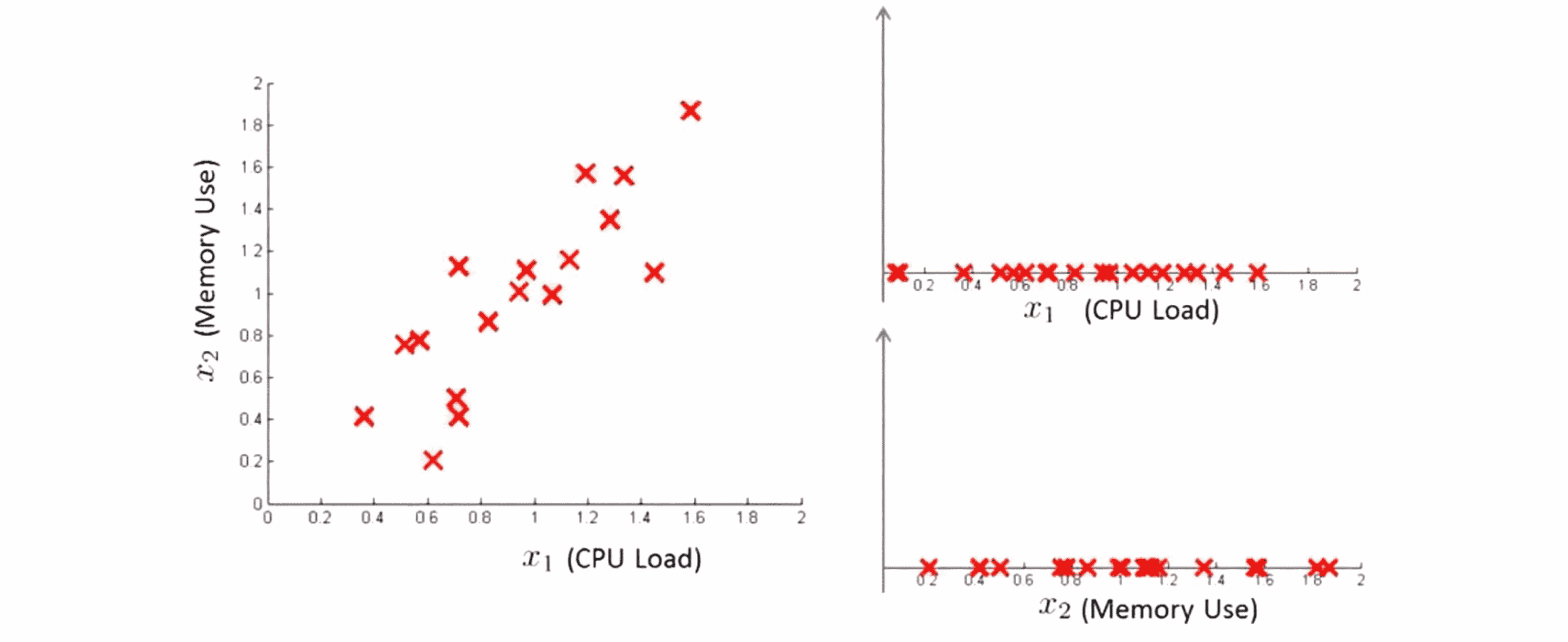
如果我们把这两个特征变量 x1 和 x2 当做高斯分布分别来建模,就会大致得到下面这样的高斯分布图像:
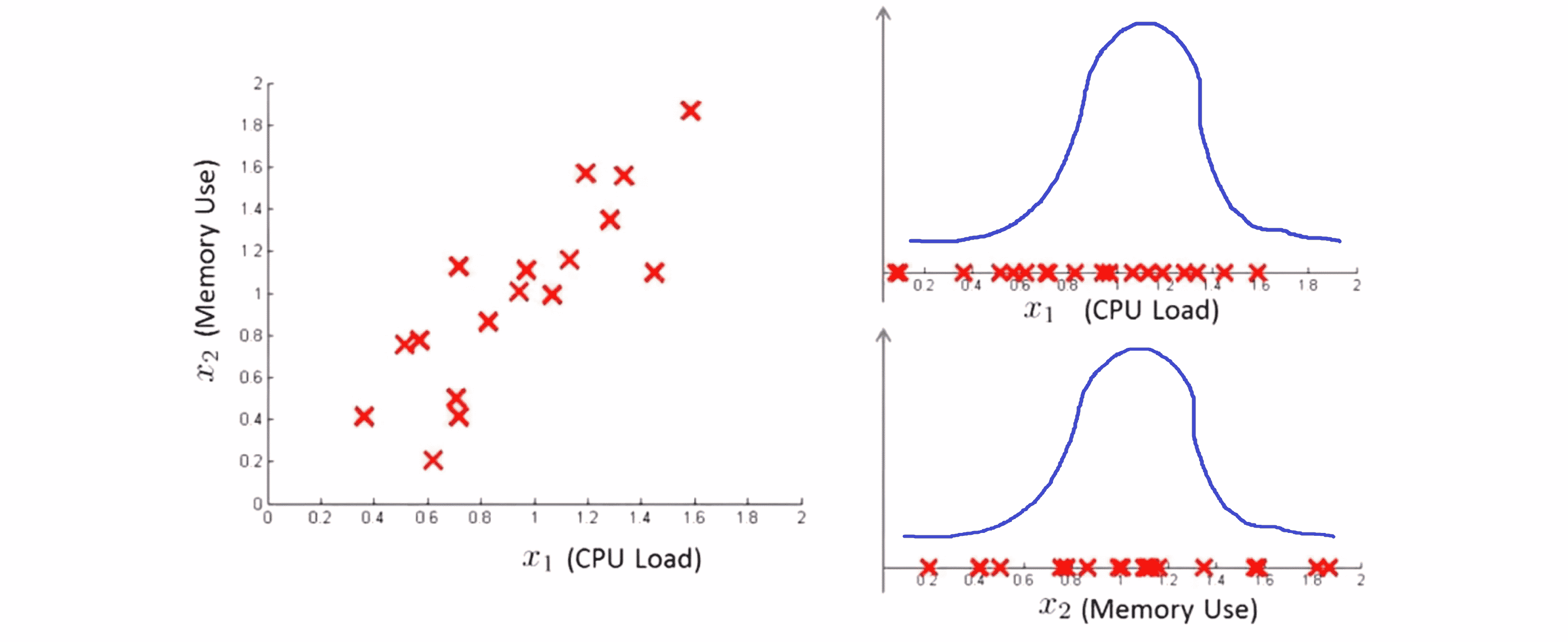
那么问题就出现了。现在假如说在测试集中有一个这样的样本,就是在绿色叉的位置,它的 x1 的值是 0.6, x2 的值是 1.6。这时如果我们分开看看这个数据点在 x1 和 x2 中的分布:
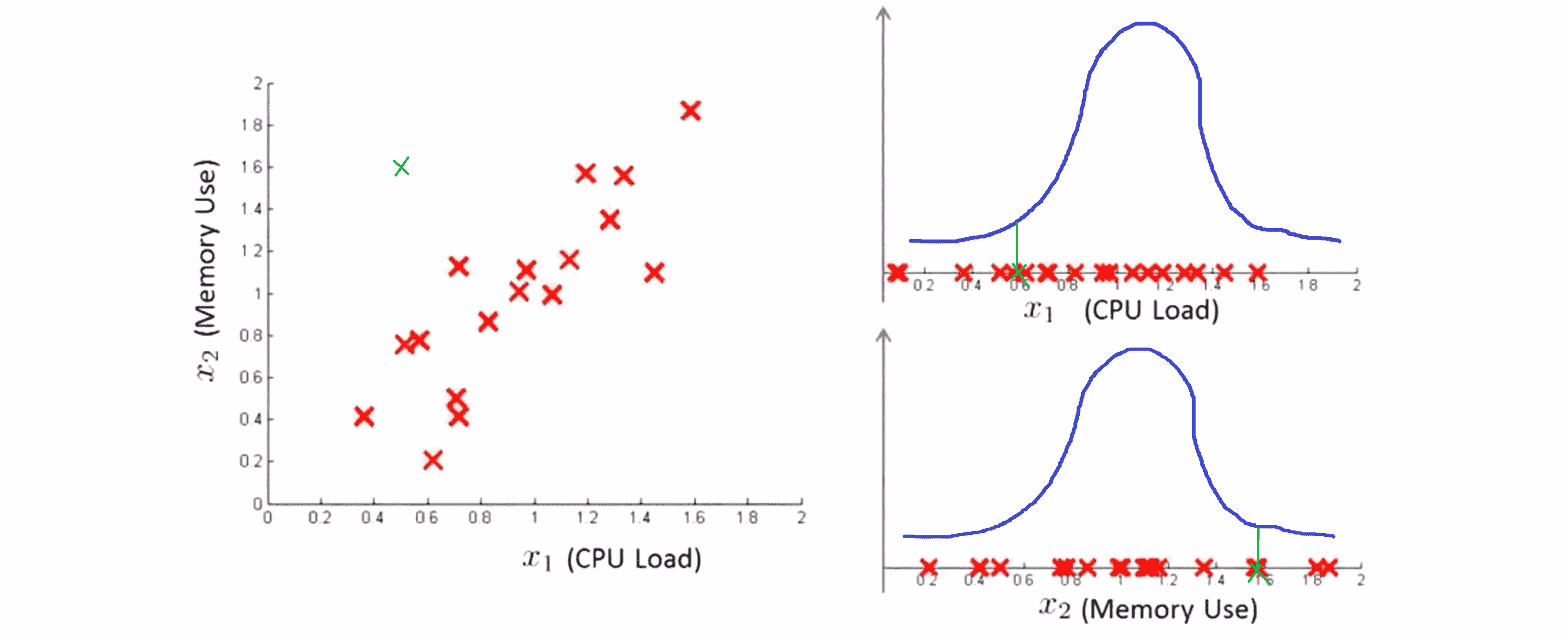
我们发现分别看 x1 和 x2,这个数据的概率似乎应该非常高,应该被当作一个正常数据;但是实际上我们看到这个绿色叉离这里看到的任何数据都很远,看起来它应该被当做 一个异常数据;矛盾就出来了。
问题出现在哪里?通过观察我们发现正常的样本的数据看起来 CPU 负载和内存使用量是彼此线性增长的关系;但是这个绿色样本看起来 CPU 负载很低但是内存使用量很高,这么看起来它应该是异常的。但是我们来看一下我们之前的异常检测算法会怎么做,对于 CPU 负载这个绿色叉差不多在 0.6 这里,因此有有相当高的可能性;相对的对于内存使用量差不多 1.6 ,它在这个高斯分布的尾部,但是可能性依然很高。所以 p(x1) 会很高,p(x2) 也会比较高,导致了我们最后的 p(x) 就会很高,导致误判。至于具体原因就是我们现在的算法只能拟合与坐标轴平行轴的椭圆划分区域。
那我们要如何改进呢?
多元高斯分布
为了解决这个问题我们要开发一种改良版的异常检测算法,这种要用到一种叫做多元高斯分布的东西 所以这,下面我们就先来了解一下多元高斯分布。
假设我们有 n 维实数构成的特征 x ,我们要做的不是把 p(x1) p(x2),分开而直接建立一个 p(x) 整体的模型,换句话说就是一次性建立 p(x) 的多元高斯分布的参数模型。类似于之前普通的高斯分布模型,这个模型的参数包括向量 µ 和一个 n×n 矩阵 Σ,Σ 被称为协方差矩阵,其性质类似于我们之前在学习 PCA 也就是主成分分析的时候所见到的协方差矩阵。对于一个给定的测试集元素 x ,其出现概率p(x)满足如下公式:
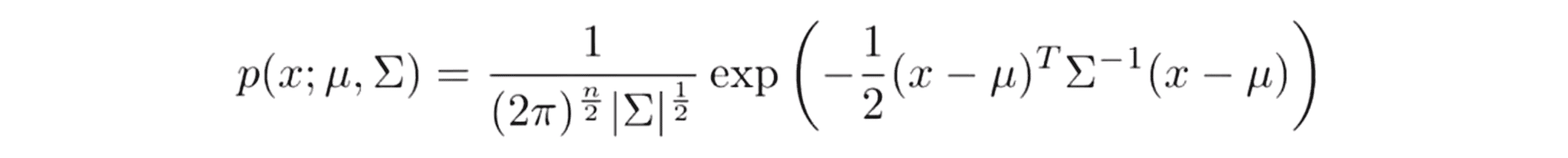
其中|Σ|这个东西叫做 Σ 的行列式 (determinant),它是一个矩阵的数学函数,我们可以直接使用 Octave 中的命令 det(Sigma) 来计算它。
说了这么多,p(x) 到底是什么样子?让我们来看一些多元高斯分布的例子来理解一下。
首先我们让 µ = [0,0] ,然后让 Σ 等于单位矩阵(identity matrix),在这个情况下 p(x) 看起来会是下面这样:
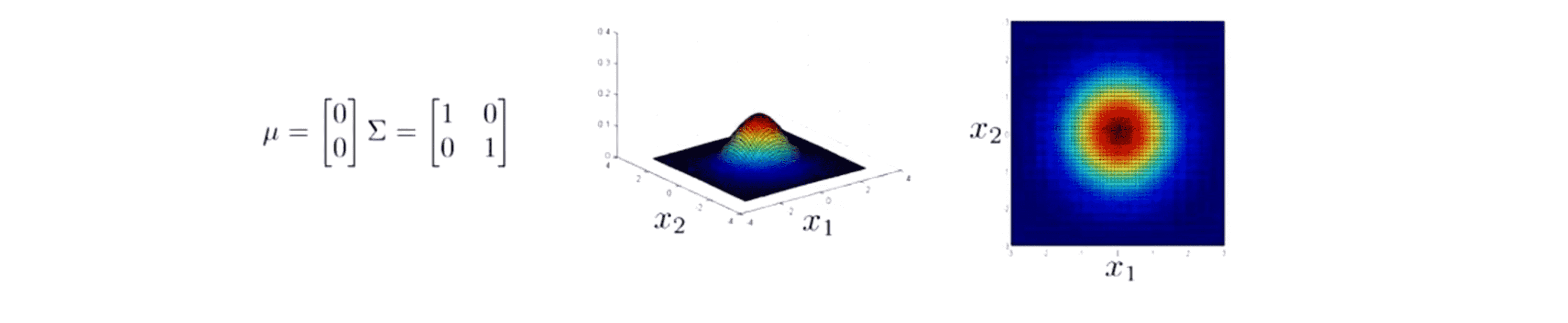
对于一个特定的 x1 的值和一个特定的 x2 的值,上图中这个面的高度就是 p(x) 的值。在这个参数设定下 p(x) 在 x1 和 x2 都等于 0 时最高,那就是高斯分布的峰值。然后这个二元高斯分布概率随着这个二维钟形的面衰减。右边那幅图和中间是一样的,但它是用等高线或者说不同颜色来描绘高度的。中间这里这个很强烈的暗红色对应的是最高值,然后这个值降低,黄色表示低一点儿的值,青色表示更低一些的值,最后这里的深蓝色表示的是最低的值。所以这两个其实是同一张图。
现在我们来试试改变一些参数,然后看看会发生什么。我们来改变一下 Σ 假如说缩小一下 Σ ,Σ 是一个协方差矩阵衡量的是方差,或者说特征变量 x1 和 x2 的变化量。所以如果缩小 Σ 那么你的得到的是鼓包的宽度减小高度增加的曲面:
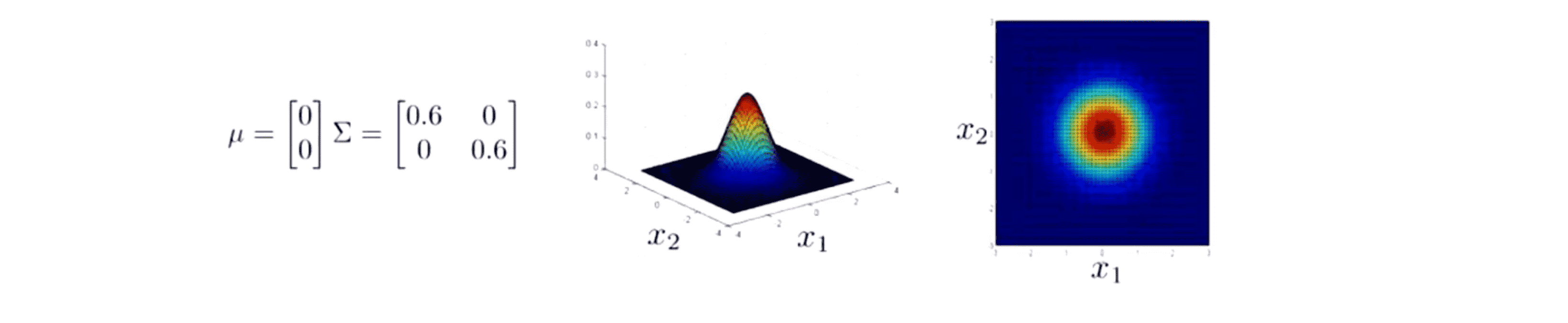
因为在这个面以下的区域体积恒等于 1 ,而我们缩小缩小 Σ ,相当于缩小方差,所以我们会得到一个窄一些 高一些的分布。而且我们看右边的俯视图也看到这些同心椭圆也缩小了一些。
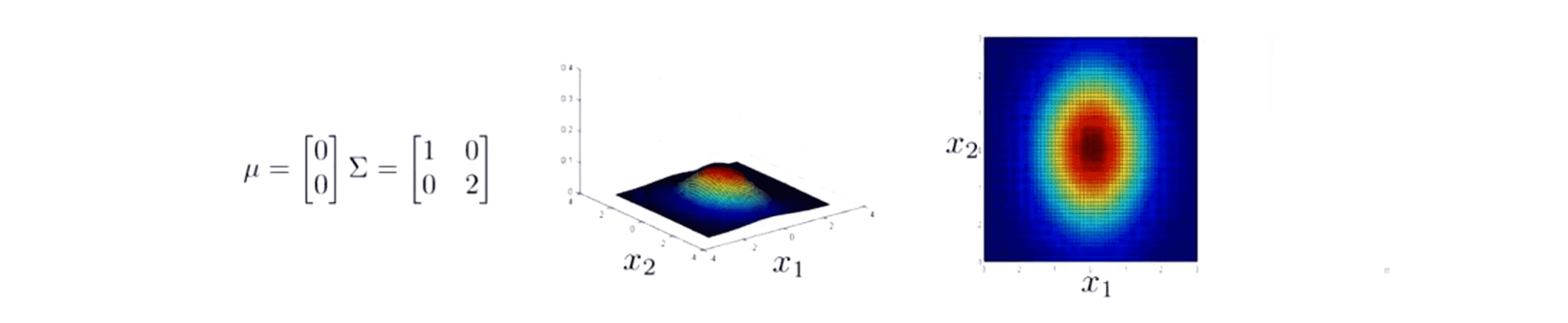
而相对的如果我们增加 Σ 对角线上的值到 2 2,我们最后就会得到一个更宽更扁的高斯分布:
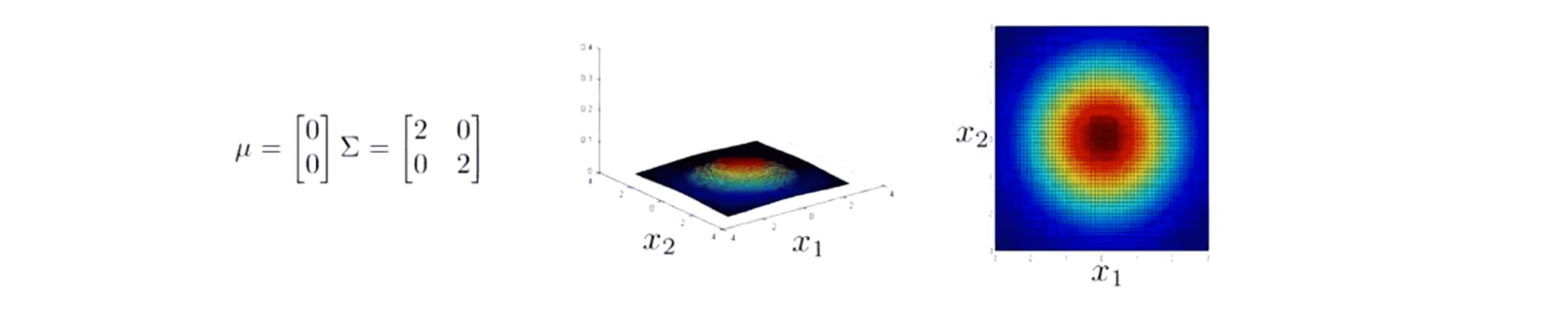
虽然很难看出来,但这还是一个钟形的鼓包它只是扁平了很多。
下面再举几个例子现在我们试一下一次改变 Σ 的一个元素。假如说我把 Σ 改为这里是 0.6 和 1 ,它所做事情的是减小第一个特征变量 x1 的方差同时保持第二个特征变量 x2 的方差不变,在这个参数设置下就可以对 x1 有小一些的方差而 x2 有大一些的方差的模型进行建模:
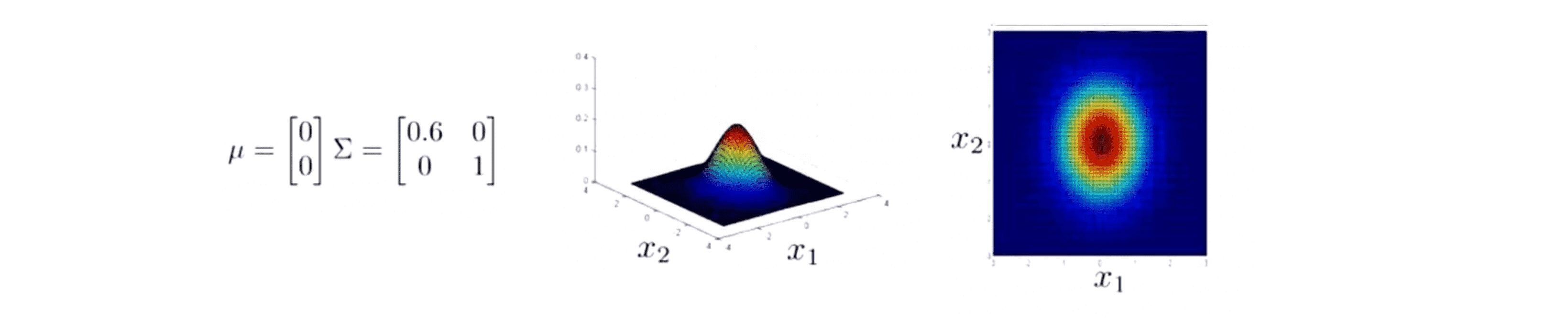
而如果把这个矩阵设置为 2 1,那么我们也可以建立 x1 的变化范围比较大而 x2 的变化范围则窄一些的模型:
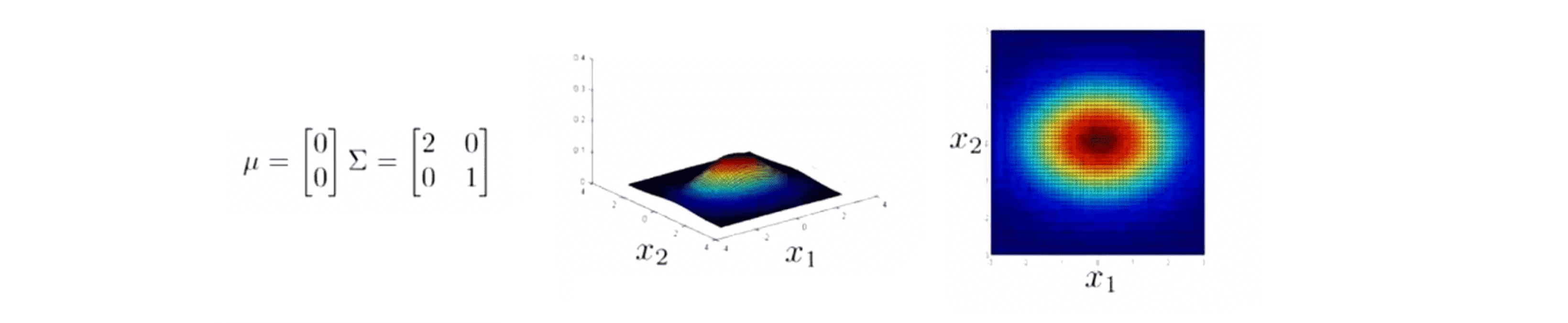
类似地如果我们改变矩阵的右下角元素,那么会类似于上一页,把 x2 改成0.6 后, x2 的变化区间非常小:
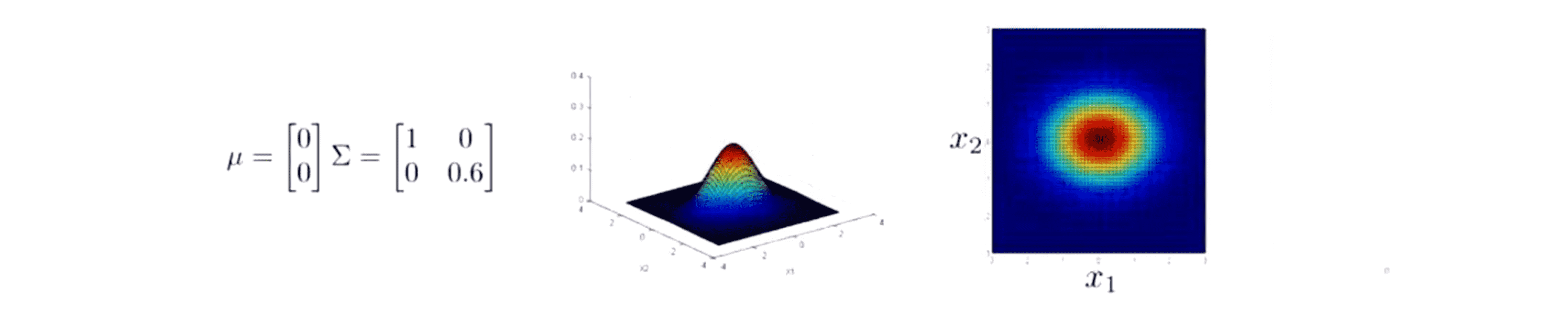
然而如果我要让 Σ 右下角的元素等于 2,这就是说让 x2 有大一些的变化区间,这样图像就会说下面这样:
现在多元高斯分布的一个很棒的事情是我们可以用它给的数据的相关性建立模型,通过改变协方差矩阵和μ来得到不一样的模型。
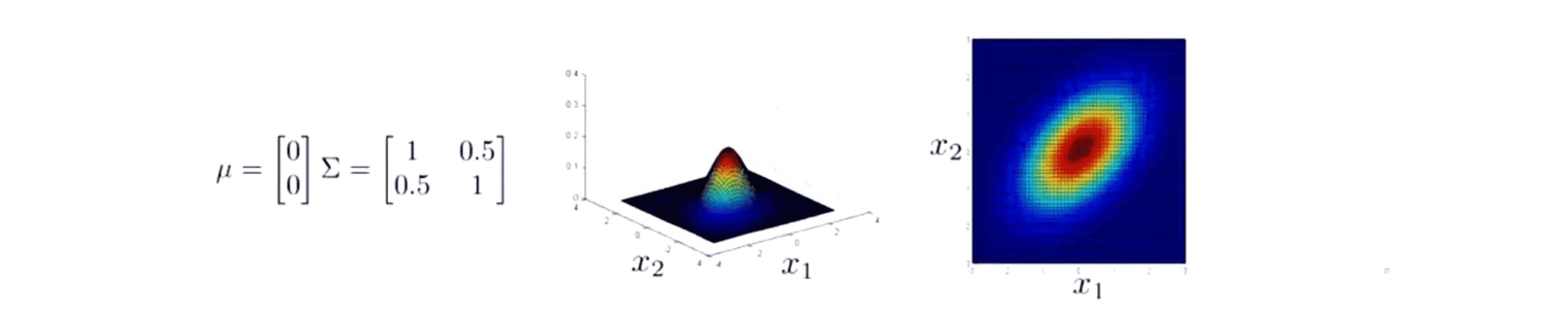
下面我们来实数改变 Σ 非对角线上的元素。比如当我们在非对角线上都加上0.5后,就会德奥下面这种非常不同的高斯分布:
我们继续将这个值增大到 0.8 ,我们会得到这样下面一个高斯分布,差不多全部的概率都在一个很窄的范围内也就是 x ≈ y,即我们会得到一个更加窄和高的沿着 x = y 这条线的分布的图像:
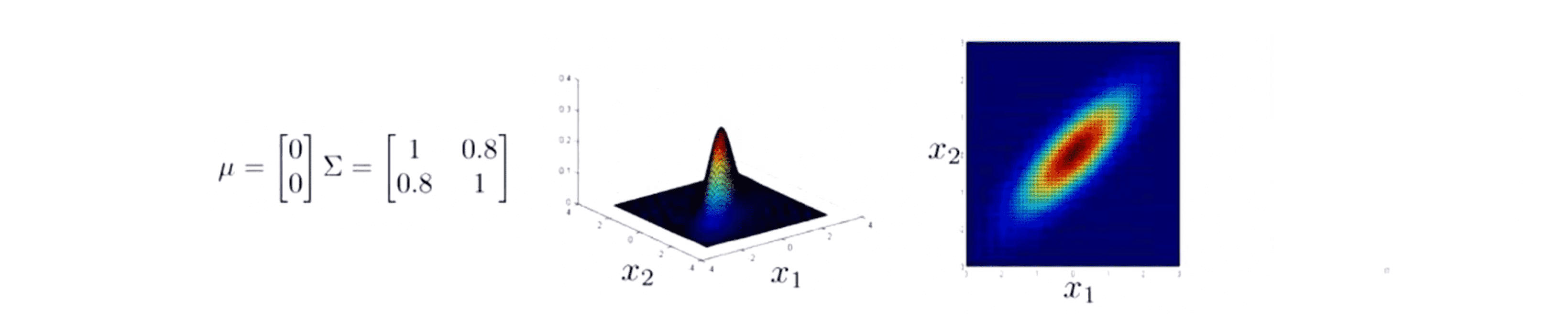
右边这个等高线图告诉我们 x 和 y 看起来是一起增加的。 概率高的地方要么 x1 很大 x2 也很大要么 x1 很小 x2 也很小。它是一个非常高而且非常薄的分布,几乎完全在 x 非常接近于 y 的这样一个非常窄的范围内。
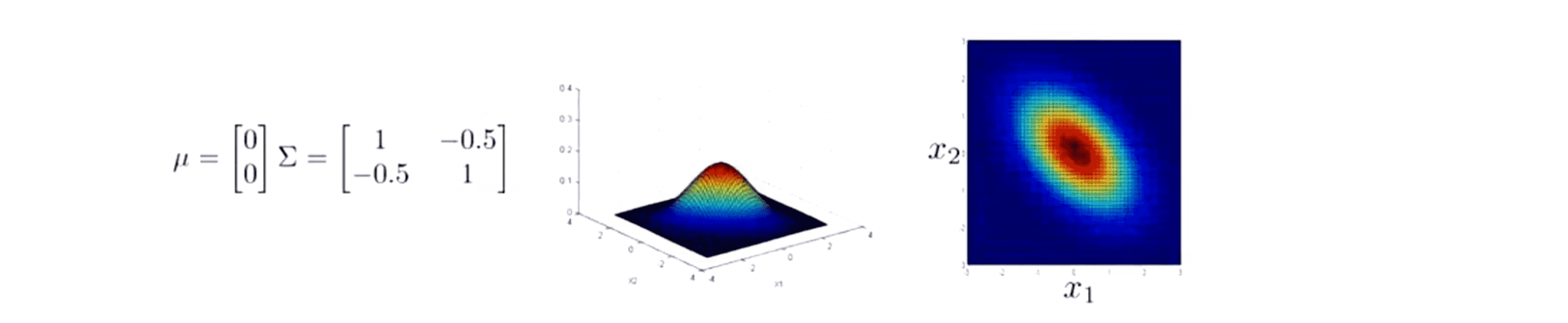
这是当我们把这些非对角线元素都设置为正数时的情况。相对地如果我们将它们设置为负数,比如都是-0.5,图像就是下面这样的:
而当非对角线元素从 -0.5 减小到 -0.8时,我们得到的模型是大部分的概率都在 x1 和 x2 负相关的这样一个区域内:
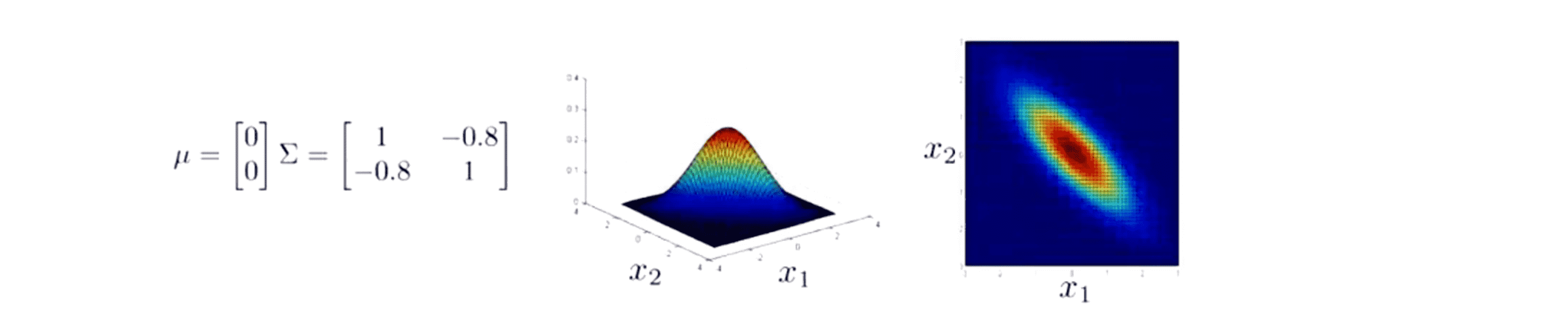
同样地,大部分点都落在 x1 ≈ -x2 的直线附近。因此这就是一个能让你体会到多元高斯分布所能展现的不同的分布。
到目前为止我们一直在改变协方差矩阵 Σ,我们还可以做的事情就是去尝试改变平均值参数 µ。我们的 µ 本来是等于 [0,0] 的,所以分布才会集中在 x1=0 x2=0 这个点周围。而如果我们改变 µ 的值,它就会改变这个分布的峰值。所以如果 µ = [0, 0.5],那么这个峰值就在 x1=0 x2=0.5 :
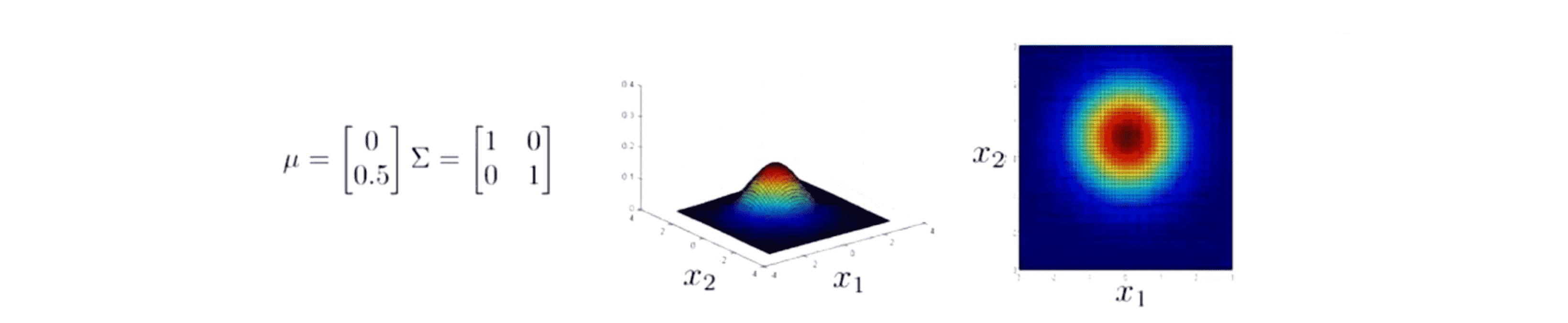
所以这个分布的峰值或者说中心就会被移动。
如果 µ 等于 [1.,5 -0.5] 那么还是同样地现在分布的峰值就会被移动到另一个地方,这个新地方就对应 x1=1.5 x2=-0.5 这个点:
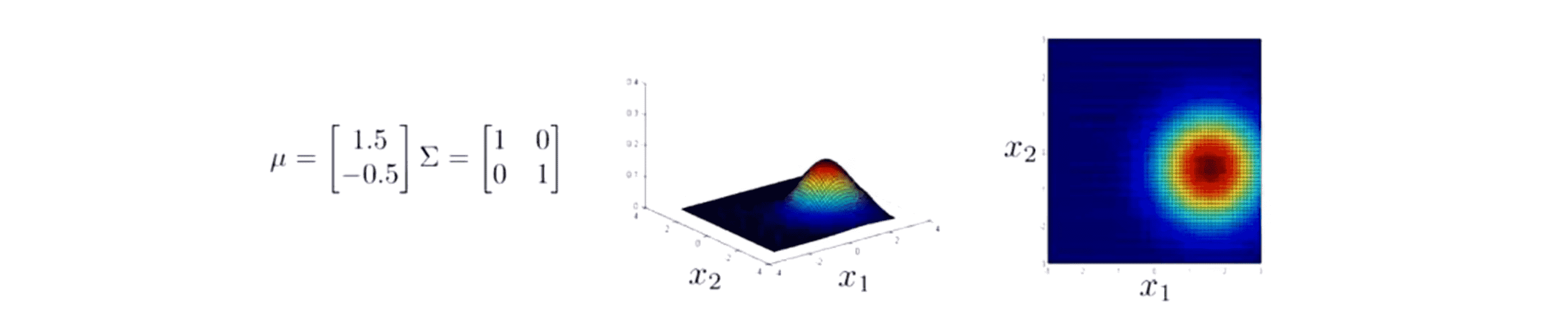
所以改变参数 µ 就是在移动这整个分布的中心,而改变 Σ 就是在改变我们曲线的形状。
希望这些不同的例子能够帮助你了解一下多元高斯分布。下一部分我们要把这个多元高斯分布应用到异常检测中对我们的算法进行升级。
应用到异常检测
在上一部分中,我们深入了解了多元高斯分布模型这一部分就让我们用它来开发另一种更加高级的异常检测算法。
首先多元高斯分布,有两个参数 µ 和 Σ,µ 是一个 n 维向量,协方差矩阵 Σ 是一个 n 乘 n 矩阵,随着我们改变 µ 和 Σ 就会得到一系列不同的概率分布:
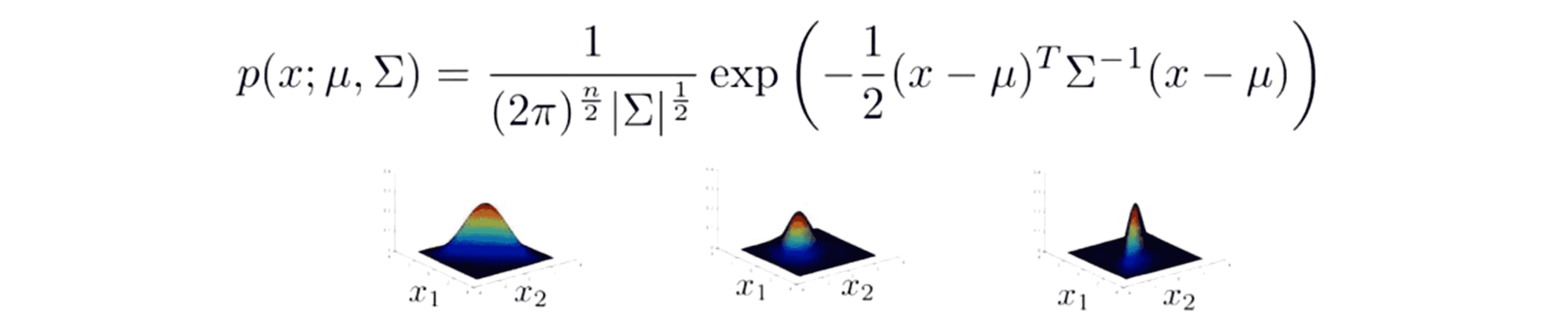
接下来让我们看看参数拟合问题或者说参数估计问题。和往常一样我们的问题是如果我们有一组样本 从 x(1) ……x(m) 这里的每一个样本都是 n 维向量而且我认为它们服从多元高斯分布,我们应该怎么估计参数 µ 和 Σ 呢?
估计它们的标准公式是这样的 µ 等于我们的训练样本的平均值,而 Σ 等于我们当时在使用 PCA 时 所写的 Σ 的式子:
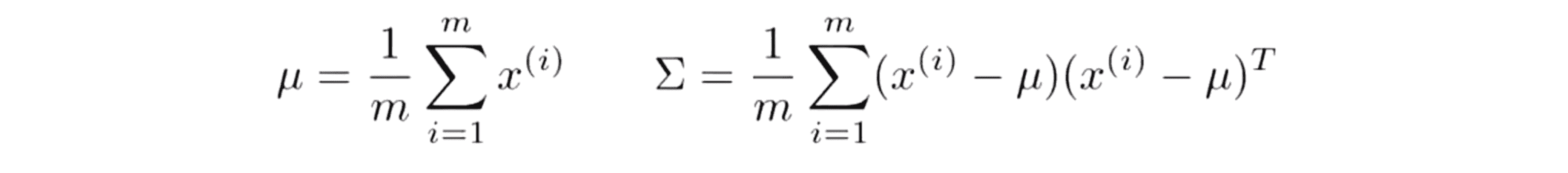
然后我们把数据代入到这两个式子中就得到了估计值参数µ 和估计值参数Σ。
如果我们来使用这个方法到异常检测算法中,我们具体应该怎么把这些放在一起来开发一个异常检测算法呢?首先我们用训练集来拟合模型以得到 µ 和 Σ;,然后我们用交叉验证集来得到我们的分界线ε;接着对于一个新样本 x ,我们要做的就是用这个多元高斯分布的公式来计算 p(x) 看看他和ε的关系;如果 p(x) < ε 那我们就把它标记为一个异常点;反之而如果 p(x) ≥ ε 那我们就不把它标记为异常点。
举个例子,如果我们要用一个多元高斯分布来拟合下面这个数据集:
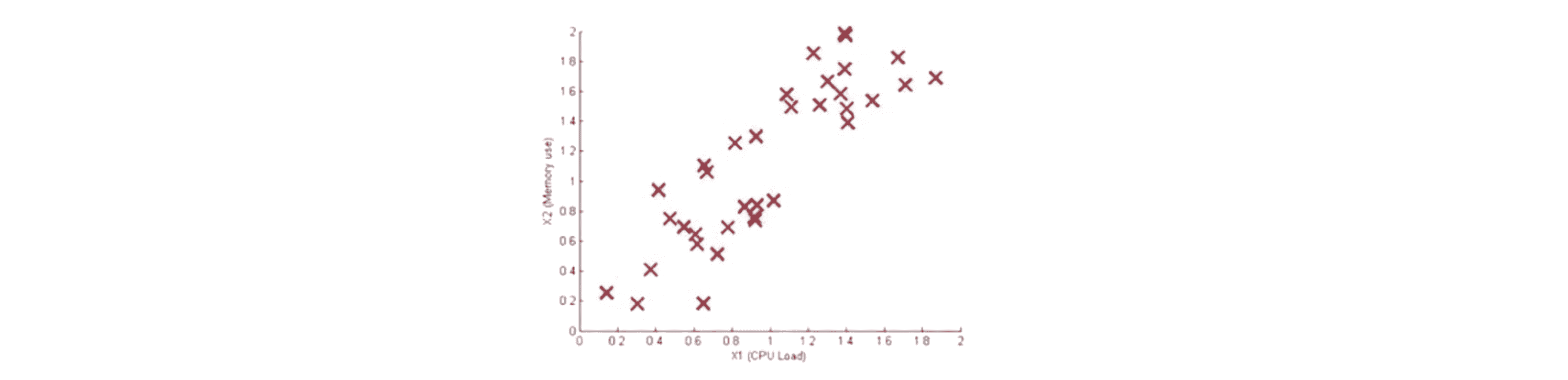
那么通过第一步我们就会得到我们的高斯分布的相关数据:

接着通过第二步我们计算出ε;
最后对于我们的测试点那个绿色的叉,我们会发现计算出来的p(x)应该相当小,所以我们的算法实际上会正确地把那个样本标记为一个异常点:
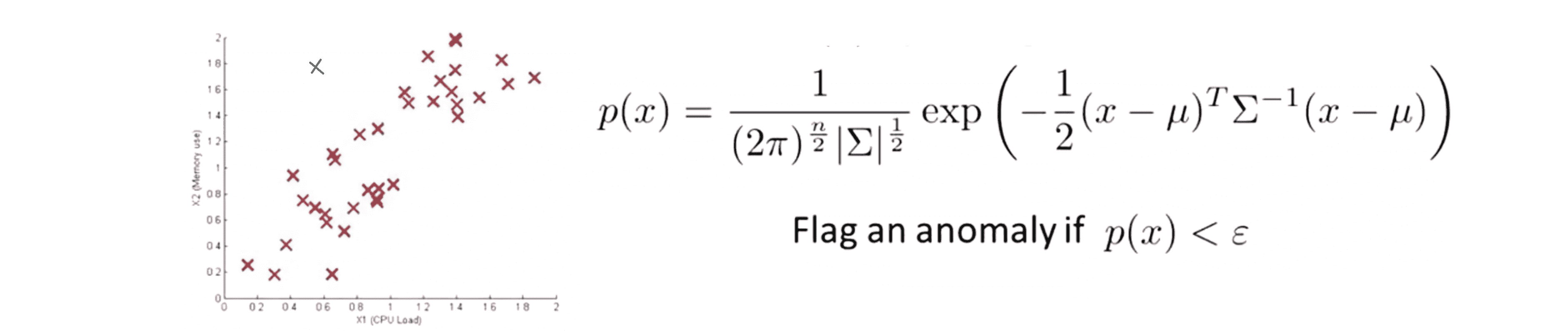
最后应该稍微说一下多元高斯分布模型和原来的模型之间的关系。p(x) 在原来的模型是p(x) = p(x1) * p(x2) *……* p(xn) :
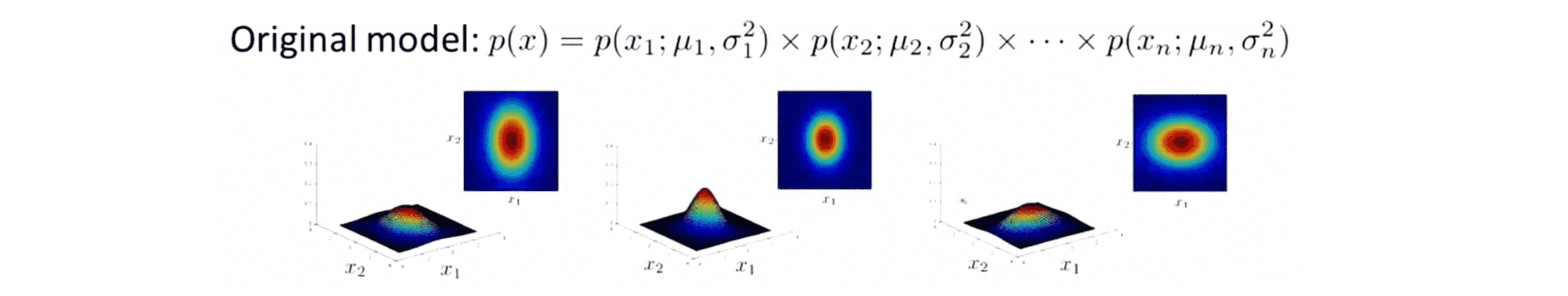
事实上我们可以从数学上证明多元高斯模型和原来的模型 之间的关系就是原来的m模型其实是我们现在多元高斯分布的一种特殊情况,其对应于的一种等高线全部都是沿着轴向的多元高斯分。 当我们取协方差矩阵 Σ 为对角矩阵,即下面这样时,那么这两个模型实际上就完全一样了:
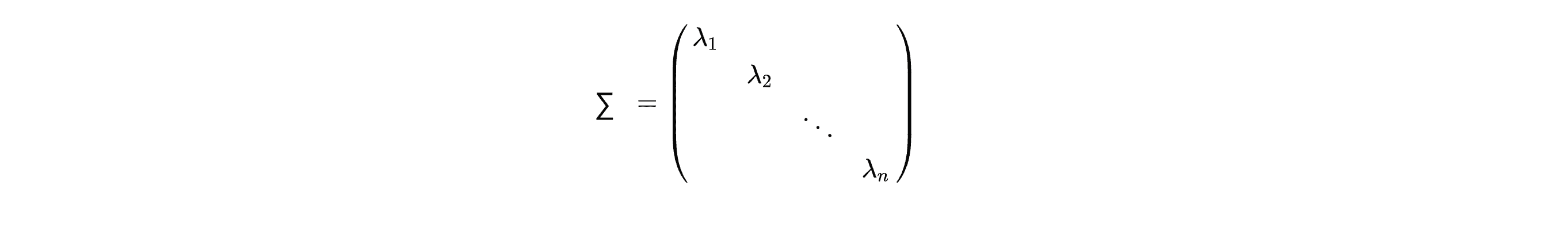
所以我们应该在什么时候用哪个模型呢?具体来说我们应该在什么时候该用原来的模型,什么时候该用多元高斯模型呢?
对于某些问题。如果你想捕捉到这样的异常比如说特征变量 x1 x2 的值的组合是不正常的——比如 CPU 负载和内存使用量的值的组合是不正常的,如果我们想用原来的模型捕捉到这个情况就需要建立一个新特征变量比如说 x3=x1/x2 代表 CPU 负载除以内存使用量来进行检测,但是多元高斯分布有能够捕捉特征变量之间的相关性的优势可以自动进行检测。如果你愿意花时间手动建立这样的新特征变量,那么原来的模型可以很好更快地运行,而相对地如果你比较懒多元高斯模型也可以帮你自动捕捉不同特征变量之间的相关性。但是原来的模型在运算量上有着绝对的优势,你想原来的模型非常简单,即便 n 等于 10,000 或者 n 等于 100,000 原来的模型通常都可以很好地运行,而对于多元高斯模型我们要计算矩阵 Σ 的逆矩阵,在这里 Σ 是一个 n 乘 n 的矩阵,而如果我们要计算的 Σ 是一个 100,000 * 100,000 的矩阵,那么这个计算量会非常大。这就取决于你是想你干的活多一点还是计算机干的活多一点。
接着是对于原来的模型事实上即使我们的训练集相对较小它也能运行得还可以,可能既视 m 是 50 或者 100 之前的模型也工作得很好;而对于多元高斯模型这个算法的数学性质要求我们的 m 必须远远大于 n,这是因为当 m 小于或等于 n 时我们的矩阵 Σ 是不可逆的,这时就不能使用多元高斯模型。在实际中,我们只有在 m 大于等于十倍的 n 时才考虑多元高斯分布。
最后我只想简单提一个技术上的性质,如果我们想拟合多元高斯模型但协方差矩阵 Σ 是不可逆的,一般只有两种情况:第一种是它没有满足这个 m 远远大于 n 的条件;第二种情况是我们有冗余特征变量。冗余特征变量的意思是我们存在着几个线性相关的特征变量。这时我们就要手动剔除掉这些特征变量来让我们的程序正常运行。
但不用担心,遇到这个问题的可能性非常低,大多数情况下只要 m 大于 n 我们都可以直接应用多元高斯模型不需要担心 Σ 不可逆的问题。
结语
以上就是多元高斯分布下的异常检测的全部,相信通过这几篇BLOG你已经初步掌握了异常检测算法。最后希望你喜欢这篇BLOG!


4 comments