在之前的BLOG中,我们学习了SVM的实现原理和让SVM如虎添翼的高斯核函数,在这篇BLOG里,就让我们来看看SVM的实现细节吧。
软件的选择
在之前的BLOG中,我们在比较抽象的层面上讨论了支持向量机 SVM 。在这一部分我们来看看为了运行或者说使用 SVM,我们实际上需要做什么。
支持向量机算法是一个特定的优化问题,其优化目的就是最小化如下代价函数:
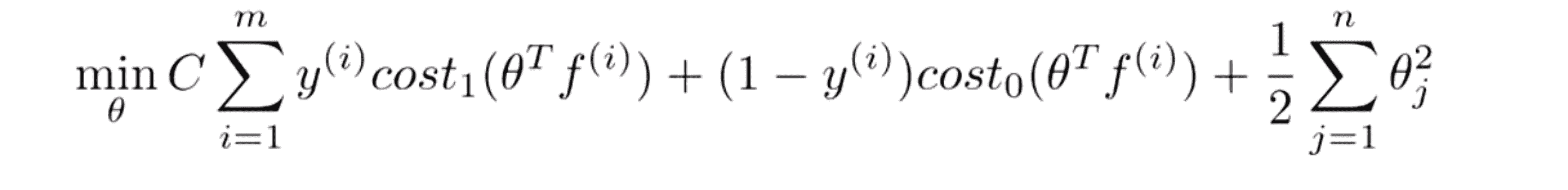
但是就如我在之前的BLOG中简单提到的,我真的不建议你自己写软件来求解参数 θ。就像如今只有很少的人或者说根本没有人会考虑自己写代码来实现对矩阵求逆或求一个数的平方根等,我们只要调用库函数来实现这些。同样地用以解决 SVM 优化问题的软件很复杂,而且已经有专门研究数值优化很多年的学者在做这个,因此如果你需要好的软件库和好的软件包来做这个,就强烈建议使用一个高度优化的软件库而不是尝试自己去实现它。
有许多好的软件库,现在人们最常用的两个是 liblinear 和 libsvm。但是真的有很多软件库可以用来实现SVM,你可以在很多主流编程语言中找到这个软件库。
核函数的选择
尽管我们不应该去写你自己的 SVM 优化软件,但是你也需要做几件事儿。
首先是要选择参数 C。我们在上一篇BLOG中讨论误差/方差的性质时,就已经提到过了这个。
接着我们也需要选择核函数或我们想要使用的其他相似度函数,这个选择是非常关键的。其中一个选择是我们选择不用任何核函数。不用核函数这个作法也叫线性核函数。因此如果有人说他的 SVM 用了线性核函数,这就意味着他在使用 SVM 时没有用核函数。这种用法的 SVM 指的是使用了 θ^T * x作为我们的决策边界。当 θ0 + θ1x1 + ... + θnxn ≥ 0时,我们预测 y = 1。对线性核函数这个术语,你可以把它理解为这个版本的 SVM 它只是给你一个标准的线性分类器,因此对某些问题来说它也是一个合理的选择。并且你知道有许多软件库比如 liblinear 就是众多软件库中的一个例子,它可以用来训练没有核函数的 SVM ,也就是带有线性核函数的 SVM。
那么我们在什么情况下会选择没有核函数的 SVM 呢?如果你有大量的特征变量,即如果 n 很大,而训练集的样本数 m 很小,那我们就会有大量的特征值和很小的训练数据集,这时我们只能去一个线性的判定边界,而不去拟合非常复杂的非线性函数,因为没有足够的数据去支持我们的拟合。如果我们想在一个高维特征空间试着拟合非常复杂的函数,而我们的训练集又很小的话,我们就很可能会过度拟合。因此这应该是我们可能决定不适用核函数或者等价地说使用线性核函数或者等价地说使用线性核函数的一个合理情况。
对于核函数的第二个选择是可以选择高斯核函数,这个是我们之前见过的:
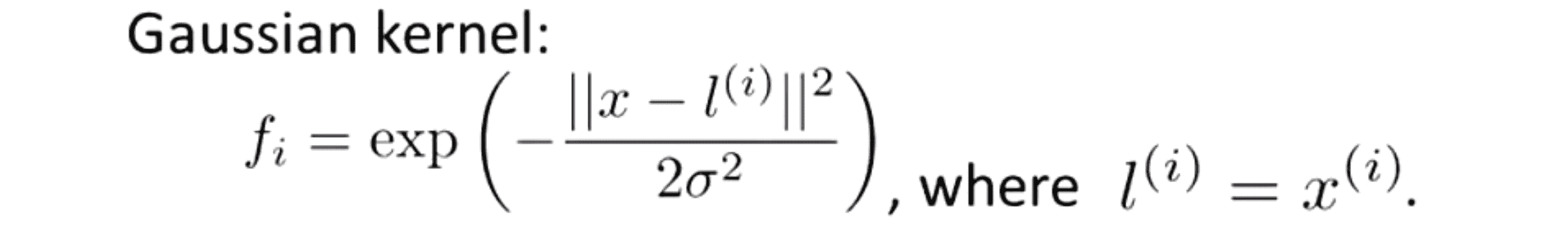
如果我们选择这个核函数,那么我们要做的另外一个抉择就是去选择一个参数 σ。我们之前讨论如何权衡偏差方差的时候也谈到过如果 σ^2 很大,那么我们就有可能得到一个较大的误差较低方差的分类器;反之如果 σ^2 很小,那么我们就会得到一个较大的方差较低误差的分类器。
那么具体在什么情况下我们才能选择高斯核函数呢?加入如果你原来的特征变量 x 是 n 维的,如果 n 很小并且理想情况下如果 m 很大,那么我们就可以通过一个核函数去拟合一个更复杂的非线性判定边界。此时高斯核函数会是不错的选择。而如果我们决定使用高斯核函数,那么下面是我们需要做的。根据你所用的支持向量机软件包,它可能需要你实现一个核函数或者实现相似度函数。因此如果我们用 Octave 或者 Matlab 来实现支持向量机的话,它会要求你提供一个函数来计算核函数的特定特征,即计算 fi 的值。我们需要做的是写一个核函数把输入进行处理返回一个实数给我们的支持向量机,其实现大概如下:

在这个例子中,我们的核函数可以通过输入的 x1 x2 向量来返回一个实数来自动地生成所有特征变量。其中 x1 一般代表训练样本 x,而 x2 表示标记点 l。
目前看来高斯核函数和线性核函数是最普遍的核函数。一个实现过程中的注意事项如果我们有大小很不一样的特征变量,在使用高斯核函数之前要记得对它们进行归一化处理。比如我们的||x - l||^2 = (x1-l1)^2+(x2-l2)^2+...+(xn-ln)^2,现在如果你的特征变量取值范围很不一样,就拿房价预测来举例.如果我们的数据的第一个变量 x1 的取值在上千平方英 的范围内,但第二个特征变量 x2 是卧室的数量是在个卧室范围内,那么 x1-l1 将会很大,然而 x2-l2 将会变得很小。在这样的情况下的话这个式子中这些间距将几乎都是由房子的大小来决定的从忽略了卧室的数量。为了避免这种情况让向量机得以很好地工作,确实需要对特征变量进行归一化,这将会保证 SVM 能够同等地关注到所有不同的特征变量,而不是像例子中那样只关注到房子的大小而忽略了其他的特征变量。
当我们尝试支持向量机时,也可以去尝试其它的的函数,但这里有一个警告,不是所有你可能提出来的相似度函数都是有效的核函数。高斯核函数,线性核函数以及其他人有时会用到的另外的核函数,它们全部需要满足一个技术条件叫作默塞尔定理 (Mercer's Theorem)。需要满足这个条件的原因是支持向量机算法或者 SVM 的实现有许多巧妙的数值优化技巧,为了高效地求解参数 θ ,在最初的设想里有一个这样的决定,将我们的注意力仅仅限制在可以满足默塞尔定理的核函数上。这个定理所做的是确保所有的SVM包都在能够使用大量的优化方法的情况下快速地得到参数 θ。大多数人最后做的是要么用线性核函数,要么用高斯核函数。
但是还有一些其他核函数满足默塞尔定理,你可能会遇到其他人使用这些核函数,然而都是人们很少很少使用的其他核函数,只是简单提及一下你可能会遇到的其他核函数。一个是多项式核函数,它将 x 和 l 之间的相似度定义为一个多项式求出来的值。比如(x^T l)^2 ,如果 x 和 l 相互之间很接近,那么这个内积就会很大。这是一个有些不寻常的核函数,它并不那么常用但是你可能会见到有人使用它,这是多项式核函数的一个变体。同样还可以是(x^T l)^3,(x^T l + 1)^5…………多项式核函数的更一般形式是`(x^T l + a)^ b`。通常这种核函数只用在当 x 和 l 都是严格的非负数时,因为这样才能保证这些内积值永远不会是负数。
我们还有可能会见到其它一些更加难懂的核函数,比如字符串核函数——如果你的输入数据是文本字符串或者其他类型的字符串,有时会用到这个核函数;还有卡方核函数,直方图交叉核函数等等……还有一些更加难懂的核函数,我们可以用它们来估量不同对象之间的相似性就不再介绍了。
多类别分类问题
我们再来看看SVM如何处理多类别分类问题。假设我们有4个类别,或者更一般地说是 K 个类别,怎样让 SVM 输出各个类别间合适的判定边界?
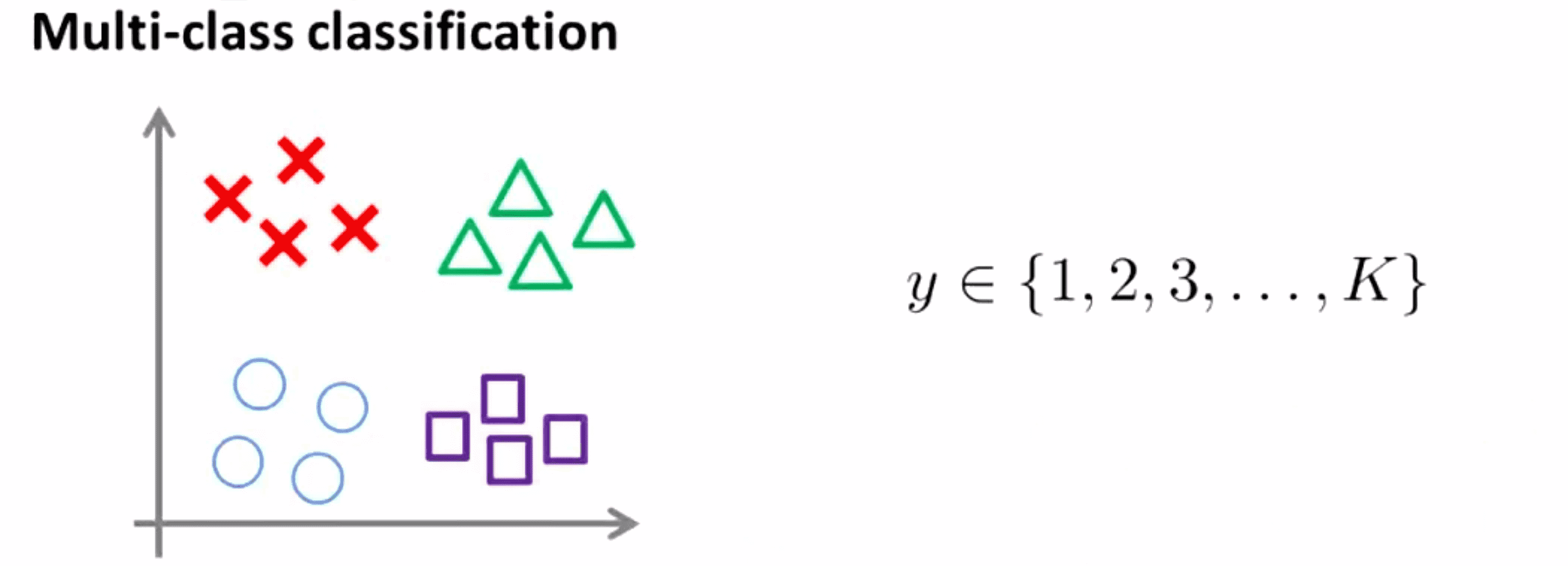
大部分 SVM 包已经内置了多类分类的函数了,因此如果我们用的是那种软件包,我们就可以直接用内置函数进行运算。如果你下载的软件包中没有内置,也不要慌张,另一个可用的方式是一对多 (one-vs.-all) 方法,这个我们在讲解逻辑回归的时候讨论过,不了解的同学可以点击这里。在这种方法下我们要做的是训练 K 个 SVM,如果我们有 K 个类别的话。每一个 SVM 把一个类同其他类区分开,这会给你 K 个参数向量,其中第一个参数向量 θ(1) 把 y = 1 这类和所有其他类别区分开 ;第二个参数向量 θ(2) 把 y = 2 和所有其他类别区分开……以此类推一直到参数向量θ(K)是用于区分最后一个类别类别 K 和其他类别的参数向量。
以上是多类分类方法.对于更为常见的情况很有可能的是不论你使用什么软件包都很有可能已经内置了多类分类的函数功能,因此你不必担心这个。
SVM vs 逻辑回归
我们从逻辑回归通过开始修改代价函数从而得到了支持向量机。最后我们还需要讨论的一点的是对这两个算法我们什么时候应该用哪个呢?
假设 n 是特征变量的个数 m 是训练样本数,那么我们什么时候用哪一个呢?如果特征变量的个数 n 相对于你的训练集大小 m 来说较大时,即当 n >> m 时,比如说如果我们有一个文本分类的问题,特征向量的维数有可能是 1 万,且如果我们的训练集大小,可能是 10 ~ 1000,那此时 n 相对 m 来说就比较大。在这种情况下我们通常会使用逻辑回归或者使用没有核函数的 SVM 或者叫线性核函数。因为如果我们有许多特征变量而有相对较小的训练集,一个线性函数就可能工作得不错,但非常复杂的非线性函数可能会出现过拟合的情况;现在如果 n 较小而 m 是中等大小,我的意思是 n 可以取 1 - 1000之间的任何数且训练样本的数量 m 可能是从 10 - 50,000个样本之间的任何一个值.那么通常高斯核函数的SVM会工作得很好.在这种情况下高斯核函数可以很好地把正类和负类区分开来;第三种值得关注的情况是如果 n 很 但是 m 很大,比如 n 还是 1 - 1000之间的数,但 m 是 十万或者更大大到上百万,如果是这样的情况那么高斯核函数的支持向量机运行起来就会很慢。在这种情况下,我们应该去寻找更多的特征变量,然后使用逻辑回归或者不带核函数的 SVM。
你发现我们总是把逻辑回归或者不带核函数的 SVM 相提并论,这是有原因的。逻辑回归和不带核函数的 SVM 其实是非常相似的算法,不管是逻辑回归还是不带核函数的 SVM,它们会做相似的事情并且表现也相似,但是根据你实现的具体情况其中一个可能会比另一个更加有效。随着你用不同的核函数学习复杂的非线性函数,你会发现样本在10,000 - 50,000 这个区间高斯核函数的支持向量机会表现得相当突出,并且这时一个非常常见的区间。最后神经网络应该在什么时候使用呢?对于所有的这些问题,对于所有这些区间,对于所有这些区间,一个设计得很好的神经网络也很可能会非常有效,它的一个缺点是或者说有时可能不会使用神经网络的原因是对于许多这样的问题,神经网络训练起来可能会很慢,但但是如果你有一个非常好的 SVM 实现包,它会运行得比较快,比神经网络快很多,所以SVM往往更受人们欢迎。
最后再提一下,尽管我们在此之前没有证明过,但实际上 SVM 的优化问题是一种凸优化问题,因此好的 SVM 优化软件包总是会找到全局最小值,或者接近它的值。对于 SVM 你不需要担心局部最优。在实际应用中局部最优对神经网络来说是一个不是非常大但是也不小的问题,但我们在使用 SVM 的时候可以少担心一个问题。根据我们的问题神经网络可能会比 SVM 慢,尤其是在我们之前提到的优势区间内。如果你觉得这里给出的参考看上去有些模糊,觉得仍然不能完全确定我是该用这个算法还是该用那个算法。这个其实没关系,当我们遇到机器学习问题时,有时确实不清楚现在选择的算法是不是最好用那个算法但从之前的BLOG我们发现算法确实很重要,但是通常更重要的是我们有多少数据,或者我们有多熟练做误差分析和调试学习算法。通常这些方面会比我们使用逻辑回归还是 SVM 这方面更加重要。
结语
通过之前我们学习的多种学习算法,我想你已经具备了在广泛的应用里构建最前沿的机器学习系统的能力,它们都是你的武器库中的非常强大的工具,希望你能妥善利用它们在工业界在学术等领域来建立更多高性能的机器学习系统。最后希望你喜欢这篇BLOG!

