从这篇BLOG开始,我们机器学习就开始进入一个新的系列——神经网络了,而这篇BLOG,就让我们来看看为什么要学习神经网络已经神经网络的一些背景吧。
非线性假设
接下来的一段时间,我们将会一同学习一种叫“神经网络”(Neural Network) 的机器学习算法,神经网络实际上是一个相对古老的算法,但后来沉寂了一段时间直到现在它才又成为许多机器学习问题的首选技术。
不过我们为什么还需要这个学习算法?我们已经有线性回归和逻辑回归算法了,为什么还要研究神经网络?为了阐述研究神经网络算法的目的,我们首先来看几个机器学习问题作为例子,这些问题的解决都依赖于研究复杂的非线性分类器。
首先先让我们来看一个监督学习的分类问题,我们已经有了如下对应的训练集:
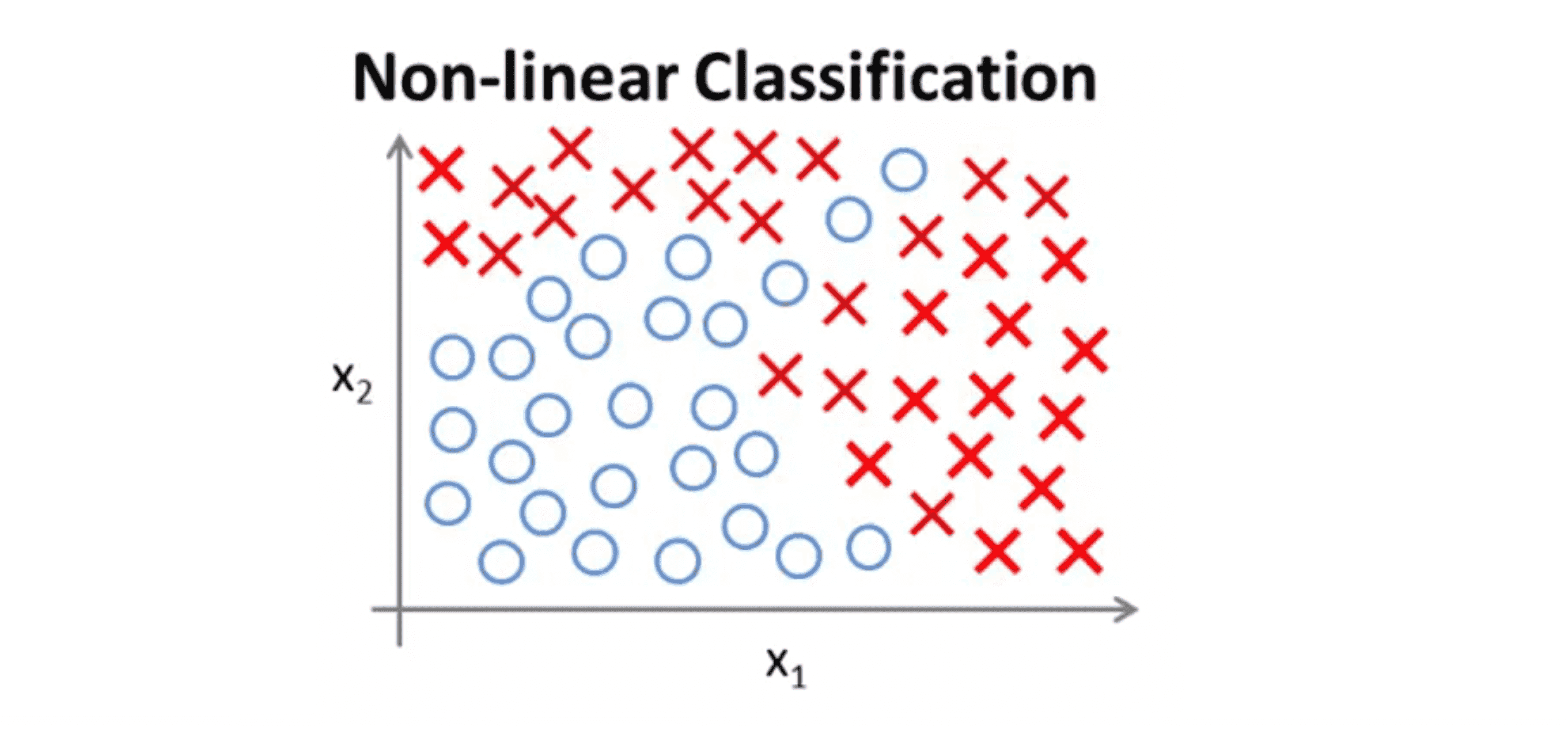
如果利用逻辑回归算法来解决这个问题,我们首先需要构造一个包含很多非线性项的逻辑回归函数,注意这里 g 仍是 s 型函数 (即f(x)=1/(1+e^-x) ) 。我们能让函数包含很多多项式项。而当多项式项数足够多时,我们就可能得到下面这样的一条分开正样本和负样本的分界线:
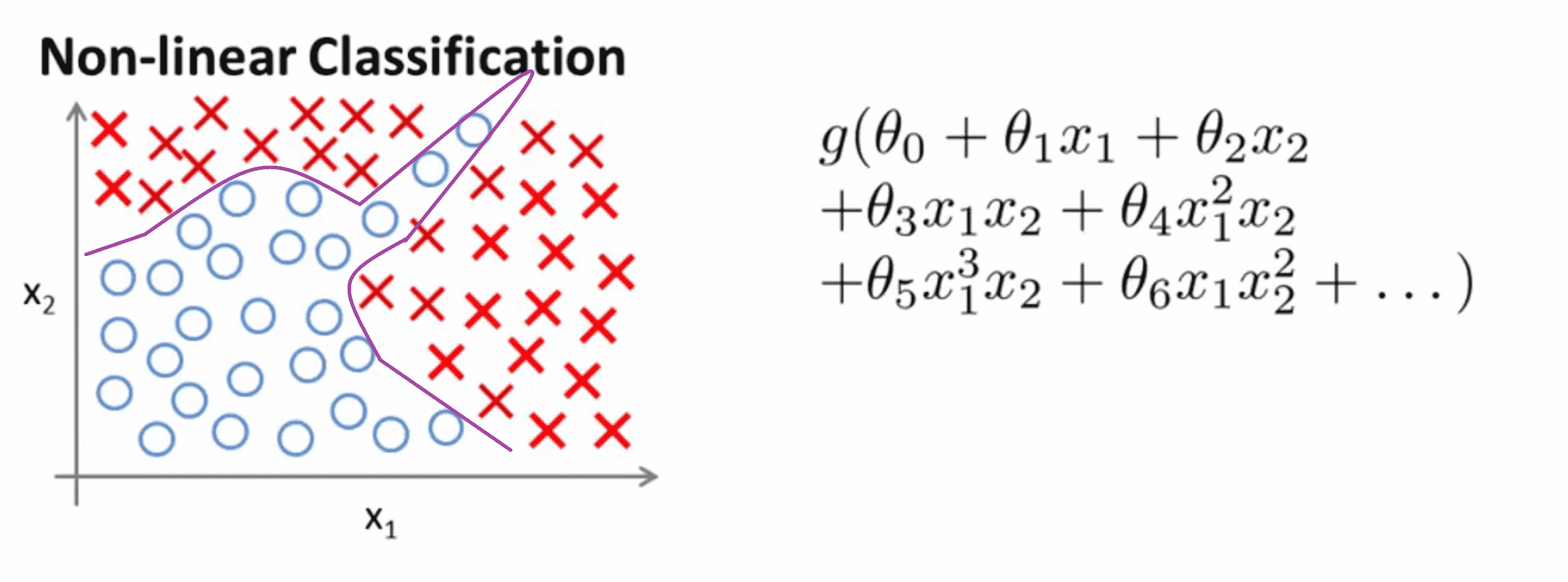
当只有两个特征值比如 x1 x2 时,这种方法确实能得到不错的结果。因为你可以把 x1 和 x2 的所有组合都包含到多项式中,且不会太繁杂。但是对于许多复杂的机器学习问题,我们涉及的特征值往往多于两项,比如我们之前讨论过的房价预测的问题,假设现在我们要处理的是关于住房的分类问题而不是一个回归问题,而一栋房子有很多方面特点,我们想预测房子在未来半年内能被卖出去的概率,这是一个分类问题 ,对于不同的房子有可能 就有上百个特征:

对于这类问题,就算只要包含所有的二次项,也有5500个项,而且随着特征个数 n 的增加,二次项的个数大约以n^2的量级增长,因此要包含所有的二次项是很困难的。所以这可能不是一个好的做法,而且由于项数过多最后的结果很有可能是过拟合的。此外在处理这么多项时,也存在运算量过大的问题。当然如果我们只考虑 x1^2 , x2^2 , x3^2直到 x100^2 这些项,这样就可以将二次项的数量大幅度减少,但是由于忽略了太多相关项,在处理类似之前那幅图的数据时,可能不能得到比较理想的结果。而现在加入也包括所有三次项,当n = 100时,我们最好大概就会得到大概 17000 个三次项。
所以当初始特征个数n增大时,这些高阶多项式项数将以几何级数递增,特征空间也随之急剧膨胀。当特征个数 n 很大时如果找出附加项来通过逻辑回归建立一些分类器显然并不是一个好做法。
而对于许多实际的机器学习问题,特征个数 n 是很大的。举个例子,我们来看关于计算机视觉中的一个问题。假设我们想要使用机器学习算法,来训练一个分类器,使可以它检测一个图像是否为一辆汽车。很多人可能会好奇这对计算机视觉来说有什么难的,毕竟当我们自己看这幅图像时,它是不是汽车是一目了然的事情,为什么学习算法竟然会不知道图像是什么。为了解答这个疑问,让我们取出这幅图片中的一小部分将其放大。比如下图中这个红色方框内的部分,当人眼看到一辆汽车时,计算机实际上看到的却是这个一个数据矩阵,其表示了像素强度值,告诉我们图像中每个像素的亮度值:

因此对于计算机来说问题就变成了根据这个像素点亮度矩阵 来告诉我们,这些数值代表一个汽车门把手。具体而言如果我们要用机器学习算法构造一个汽车识别器时,我们要准备一个分类好的样本集,其中一些样本是各类汽车,另些样本是其他任何东西;然后我们将这个样本集输入给学习算法以训练出一个分类器:

训练完毕后,我们输入一幅新的图片让分类器判定 “这是什么东西?” 理想情况下,分类器能识别出这是一辆汽车:

为了理解引入非线性分类器的必要性,我们从学习算法的训练样本中挑出一些汽车图片和一些非汽车图片,让我们从其中每幅图片中挑出一组像素点,并且在坐标系中标出这幅汽车的位置,在坐标系车的位置取决于我们选取的像素点1和像素点2的亮度,接着我们加入一些非汽车的图片用"+"表示汽车图片,用“-”表示非汽车图片:
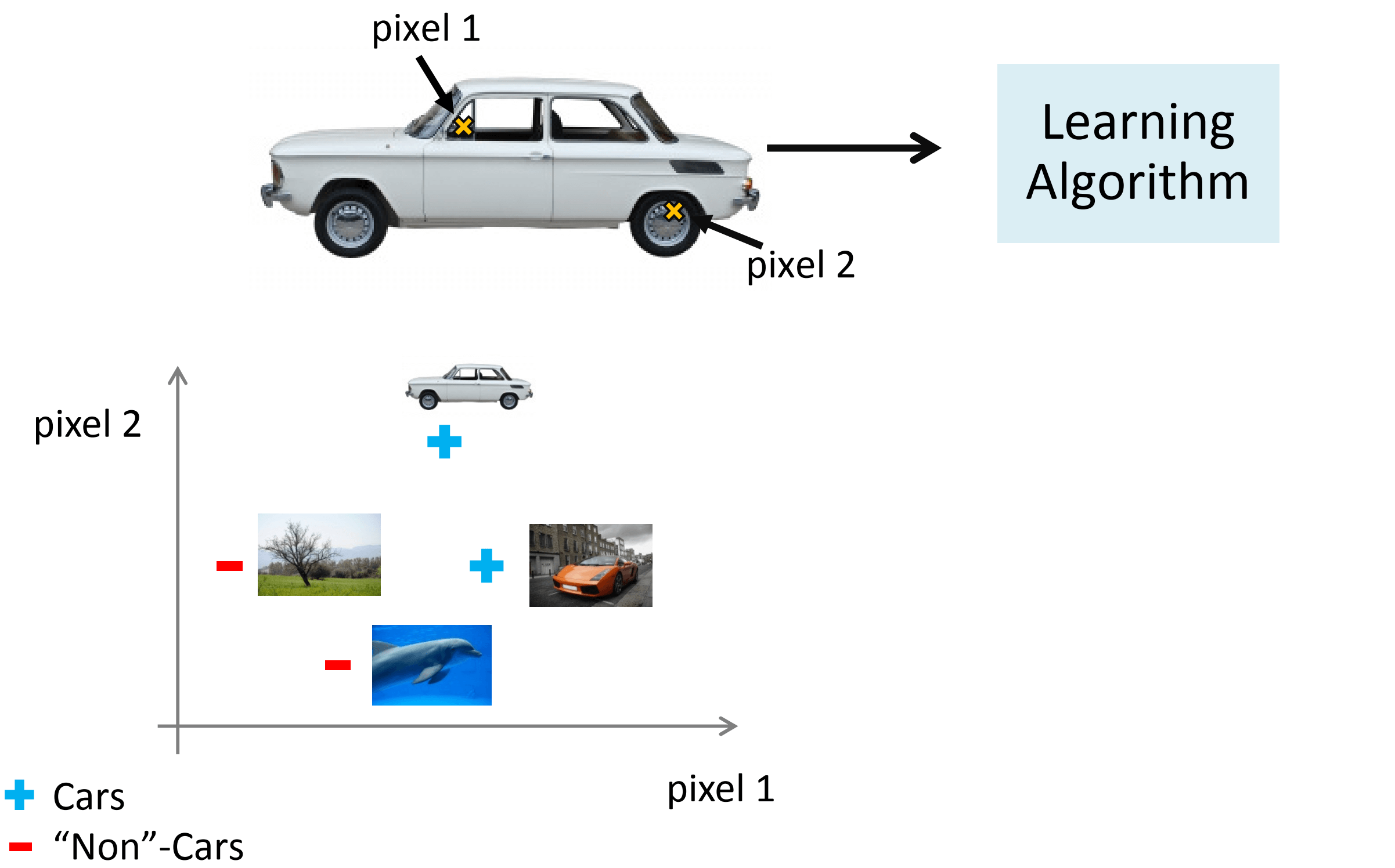
接着我们将发现汽车样本和非汽车样本分布在坐标系中的不同区域,因此我们现在需要一个非线性分类器来尽量分开这两类样本:
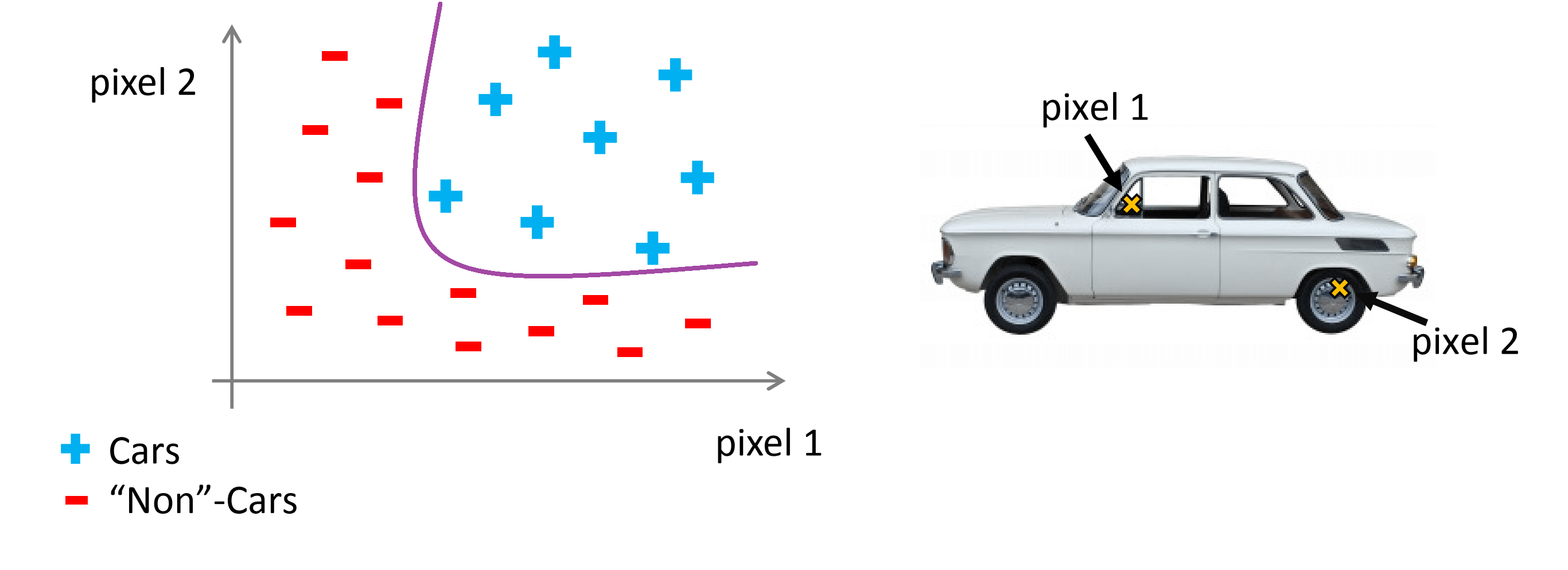
这个分类问题中特征空间的维数是多少?假设我们用50*50像素的图片,这个已经很小了长宽只各有50个像素,但这依然是2500个像素点,因此我们的特征向量的元素数是 N = 2500。特征向量X包含了所有像素点的亮度值:
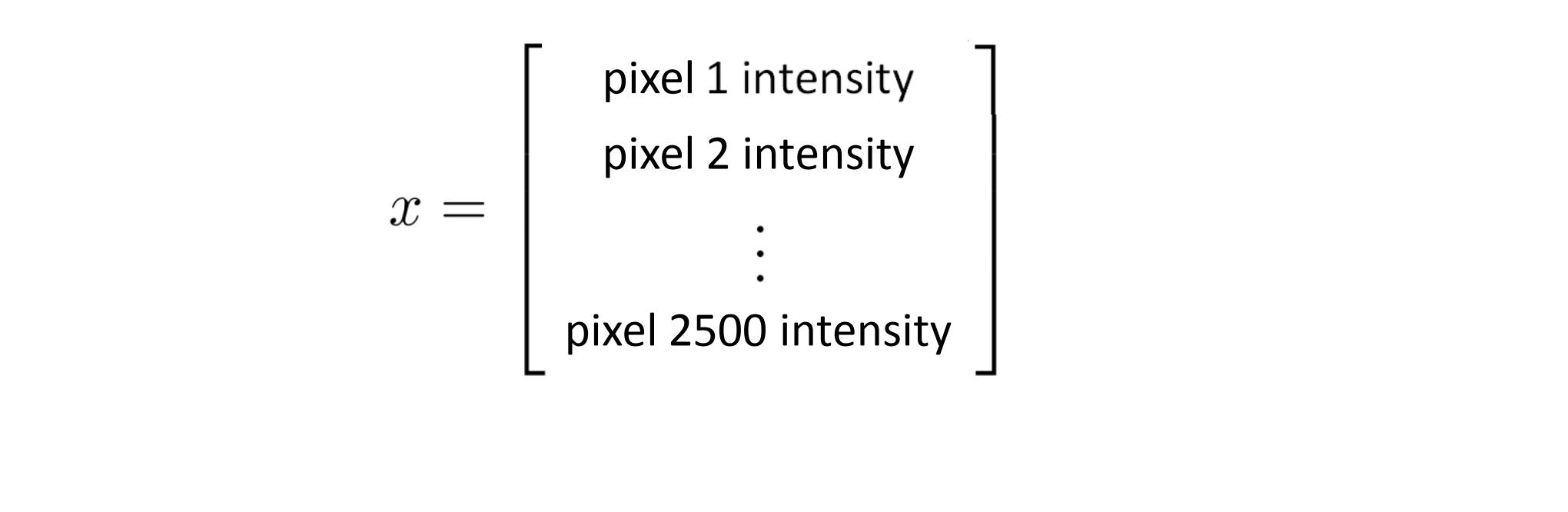
而如果存储的是每个像素点的灰度值 (色彩的强烈程度) 那么每个元素的值应该在0到255之间,且特征值个数 N = 2500。 但是这只是使用灰度图片的情况,如果我们用的是RGB彩色图像,那每个像素点就包含红、绿、蓝三个子像素,其N = 7500。因此如果我们非要通过包含所有的二次项的逻辑回归来解决这个非线性问题 ,那么我们总共大约会有300万个特征值,其实在太大了。因此只是简单的增加二次项或者三次项之类的逻辑回归算法并不是一个解决复杂非线性问题的好办法。所以之后我们会一同学习神经网络,它在解决复杂的非线性分类问题上被证明是一种好得多的算法,即使你输入特征空间或输入的特征维数 n 很大也能轻松搞定。
神经元和大脑
这一部分我们就来一同看看一些神经网络的背景知识。首先神经网络为什么会产生呢?人们想尝试设计建立学习系统, 那为什么不去模仿我们所认识的最神奇的学习机器 —— 人类的大脑呢,因此神经网络逐渐兴起于二十世纪八九十年代,且应用得非常广泛。但由于各种原因在九十年代的后期神经网络的应用减少了,但是近些年神经网络又东山再起,其中一个重要原因是神经网络计算量偏大,而近些年计算机的运行速度变快才足以真正运行起大规模的神经网络。
当我们想模拟人类大脑时,我们就是想制造出与人类大脑作用效果相同的机器,大脑可以学会去处理图像,学会处理我们的触觉,我们的大脑还能学习数学,学着做微积分,而且大脑还能处理各种不同的令人惊奇的事情。似乎如果我们想要模仿它就得写很多不同的程序来模拟大脑所有的操作。
不过能不能假设大脑做所有这些不同事情不需要用上千个不同的“学习算法”去实现,相反的大脑的处理只需要一个单一的学习算法就可以了?尽管这只是一个假设,不过让我会和你分享一些这方面的证据,证明这是真的。
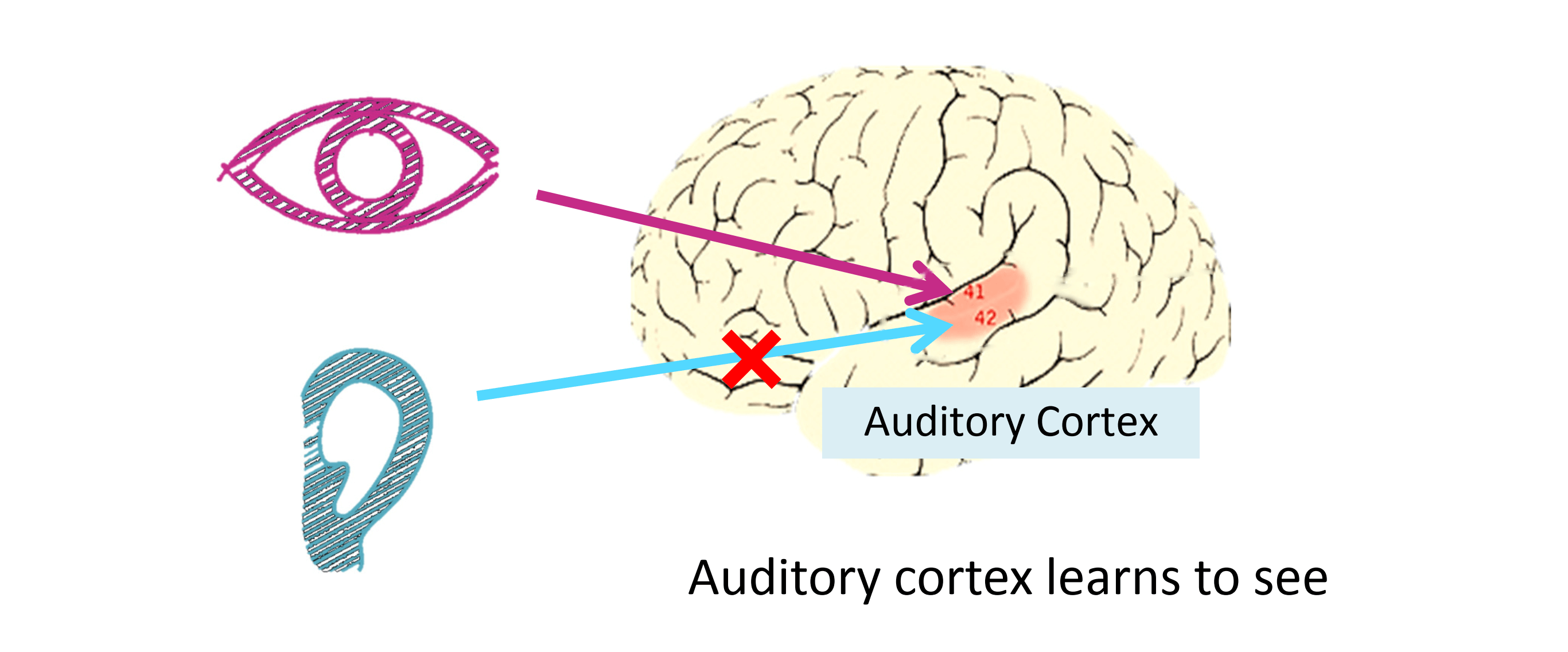
如下图,大脑的某一部分是你的听觉皮层,正因有它,我们才能明白别人说的话。神经系统科学家做了一个有趣的实验,他们把耳朵到听觉皮层的神经切断,再将眼镜连接到听觉皮层上,这样从眼睛到视神经的信号最终将传到听觉皮层,而如果这样做了,结果表明听觉皮层将会学会“看”, 这里“看”代表了我们所知道的每层含义。所以如果你对动物这样做那么动物就可以完成视觉辨别任务:
再看另一个例子,下图是大脑中用来处理触觉的某区域,如果你做一个和刚才类似的重接实验,那么躯体感觉皮层也能学会“看” :
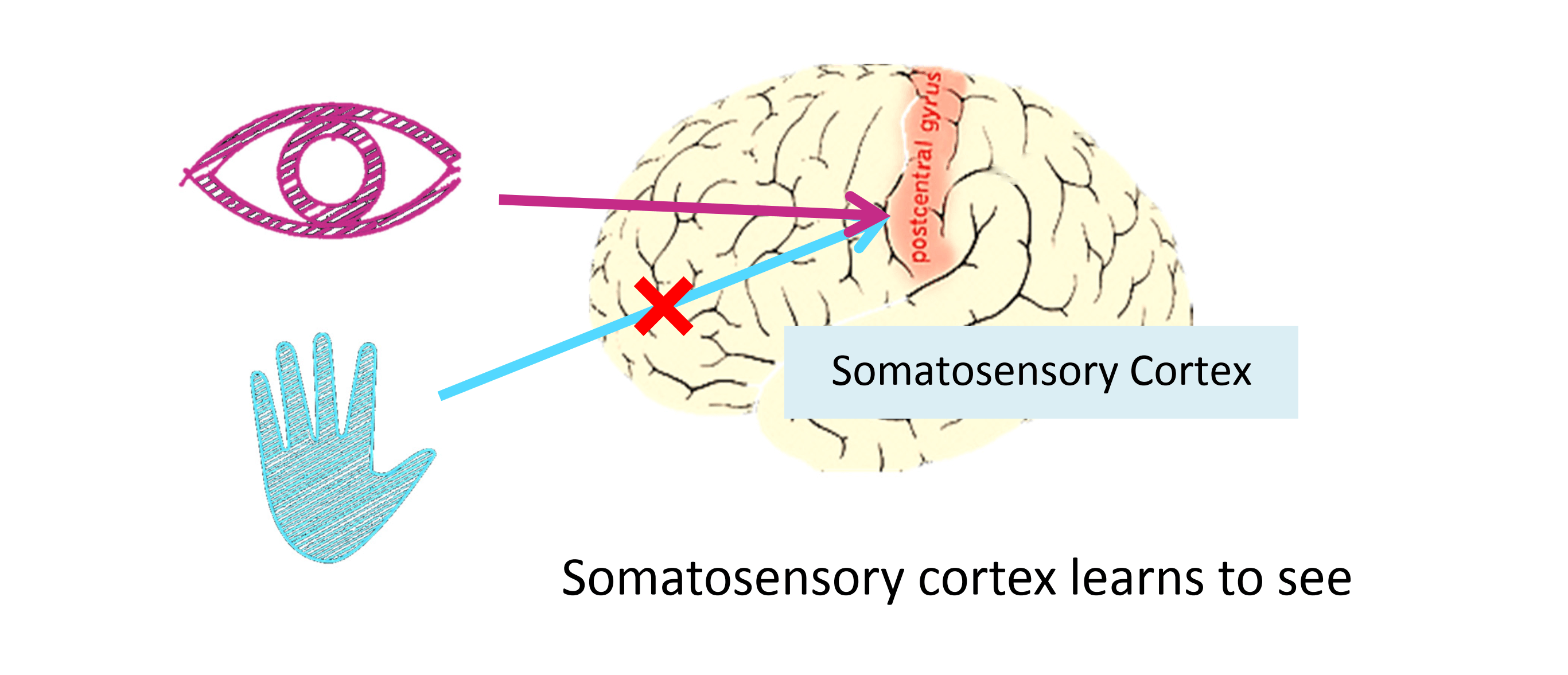
以上实验和其它一些类似的实验都被称为神经重接实验,从这个意义上说,如果人体有同一块脑组织可以处理光、 声或触觉信号,那么也许存在一种学习算法可以同时处理视觉、听觉和触觉,而不是需要运行上千个不同的学习算法。大脑所完成的成千上万的美好事情,也许我们需要做的就是找出一些近似的或实际的大脑学习算法然后实现它。大脑通过自学掌握如何处理这些不同类型的数据,在很大的程度上,我们可以猜想如果我们把几乎任何一种传感器接入到大脑的的几乎任何一个部位的话,大脑就会学会处理它。
下面再举几个例子,第一个例子是我们可以用舌头学会“看”的一个例子,这实际上是一个名为BrainPort的系统,它现在正在FDA (美国食品和药物管理局) 的临床试验阶段,它能帮助失明人士看见事物:
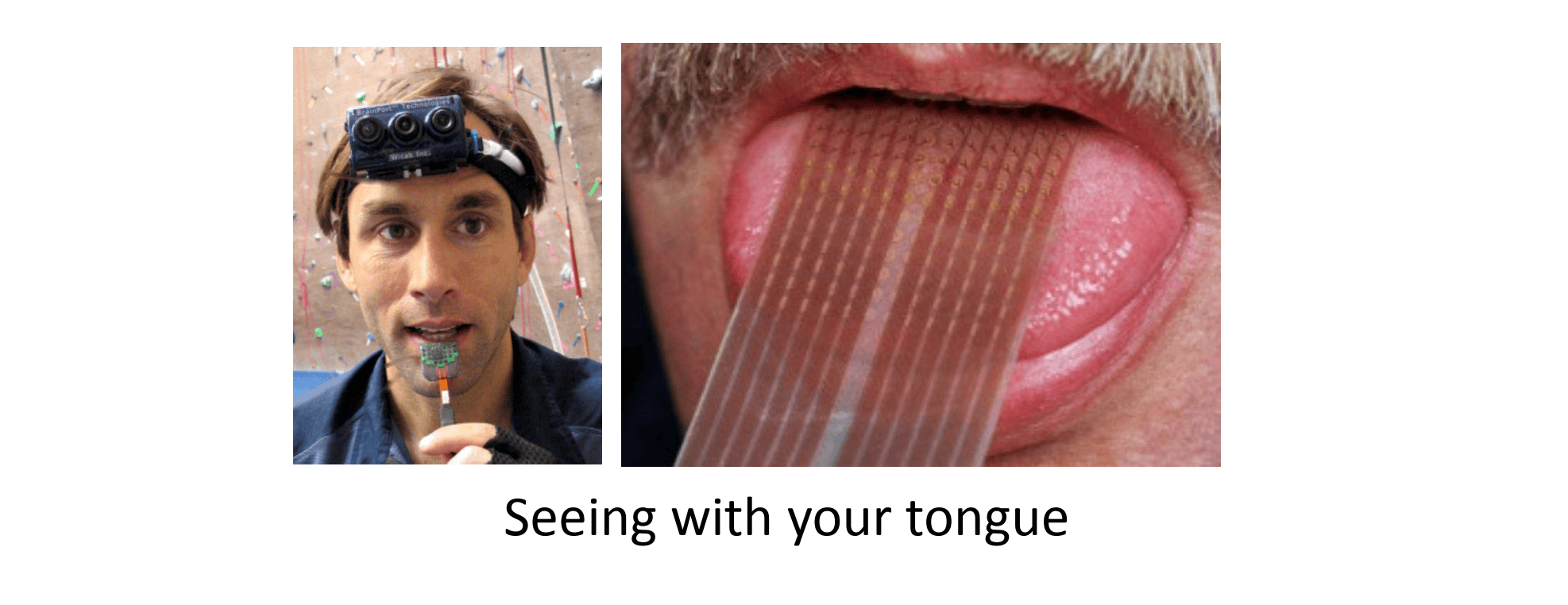
它的原理是在前额上带一个灰度摄像头,其能获取佩戴者面前事物的低分辨率的灰度图像,然后通过线连接到舌头上安装的电极阵列上,那么每个像素都被映射到舌头的某个位置上,可能电压值高的点对应一个暗像素,电压值低的点对应于亮像素。即使依靠它现在的功能,使用这种系统就能让我们在几十分钟里就学会用我们的舌头“看”东西。
第二个例子是关于人体回声定位或者说人体声纳,我们通常有两种方法可以实现,可以弹响指或者咂舌头,现在有失明人士确实在学校里接受这样的培训并学会解读从环境反弹回来的声波模式,如果你搜索 YouTube之后就会看到一些讲述了一个令人称奇的孩子的视频:

他因为癌症眼球惨遭移除,虽然失去了眼球但是通过打响指的方式,他可以四处走动而不撞到任何东西,他也能滑滑板,可以将篮球投入篮框中,非常令人感动。
第三个例子是触觉皮带,如果我们把它戴在腰上,蜂鸣器会响,而且总是朝向北时发出嗡嗡声,它可以使人拥有方向感,就是类似于鸟类感知方向的方式:

还有一个离奇的例子,如果你在青蛙身上插入第三只眼,青蛙也能学会使用那只眼睛:

这些都非常令人惊奇,你能把几乎任何传感器接入到大脑中,大脑的学习算法都能找出学习数据的方法,并处理这些数据。从某种意义上来说如果我们能找出大脑的学习算法,然后在计算机上执行大脑学习算法或与之相似的算法,我们人工智能的进程就能前进一大步。
结语
通过这篇BLOG,相信你已经对神经网络有了一点初步的了解,之后我们还会进行更加深入的讲解。最后喜欢你喜欢这篇BLOG!

