在之前的BLOG里,我们一同学习了如何使用梯度下降法来解决回归问题和分类问题,现在我们就来看看如何优化这一过程。
高级优化算法
首先让我们来换个角度,来看什么是梯度下降。
我们梯度的目的是对于代价函数 J ,我们想要找到合适的 θ ,使其最小化。在梯度下降中我们做的事情可以分为两部分:第一件事是对当前参数 θ , 编程计算出两样东西 J(θ) 以及 J 关于 θ1 到 θn 的偏导数项;假设我们已经完成了 可以实现这两件事的代码,那么我们就可以进入第二件事情-进行梯度下降,即我们利用第一件事得到的J(θ) 以及 J 关于 θ1 到 θn 的偏导数项反复执行下面的这些更新我们的参数 θ:
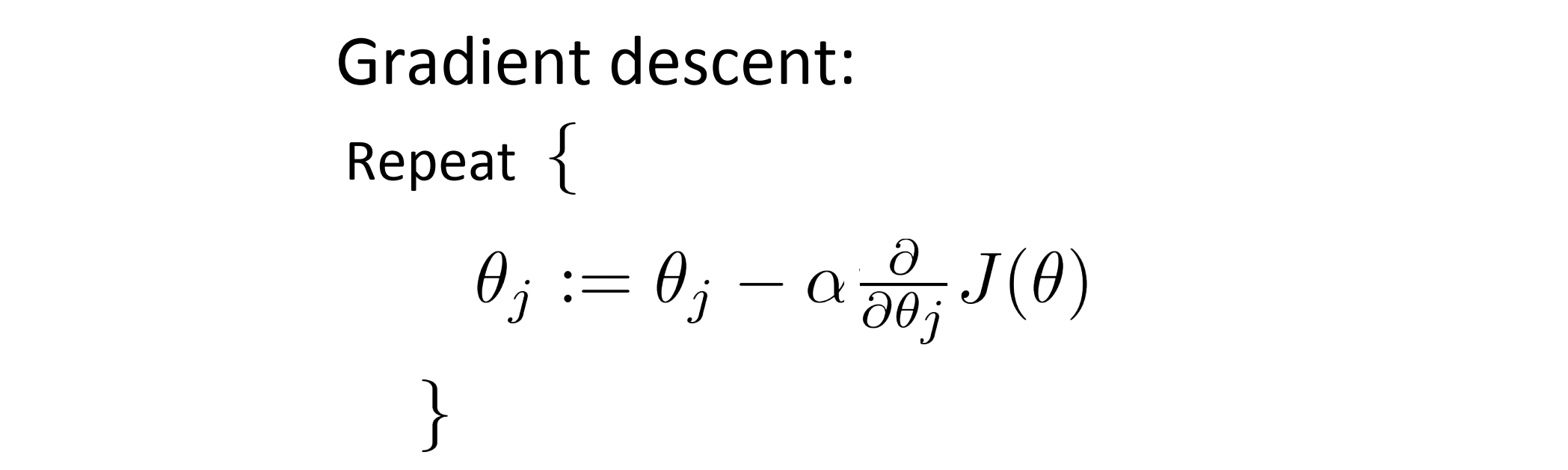
梯度下降法就把第一步计算得到的结果中的偏导数项插入第二步的更新当中从而来更新参数 θ,因此另一种考虑就是梯度下降的思路是我们需要写出代码来计算 J(θ) 这些偏导数,然后把这些结果插入到梯度下降中为我们最小化代价函数。对于梯度下降来说,从运算的需求来说,我们实际并不需要编写代码来计算代价函数 J(θ),只需要编写代码来计算偏导数项就可以了。但是如果是希望代码还要能够监控这些 J(θ) 的收敛性的话,我们就需要自己编写代码来同时计算代价函数和偏导数项了。所以在写完能够计算这两者的代码之后,我们就可以使用梯度下降。
但梯度下降并不是我们可以使用的唯一算法,我们还有其他一些更高级更复杂的算法,如果我们能用这些方法来计算的话,我们计算得到代价函数的最优情况的速度就会大大缩减。
比如共轭梯度法 BFGS (变尺度法) 和 L-BFGS (限制变尺度法) 就是其中一些更高级的优化算法,它们需要我们计算 J(θ) 和偏导数项并提供给这些算法,然后它们就会自动地去寻找 J(θ) 的全局最小点。即我们的算法流程大致如下:
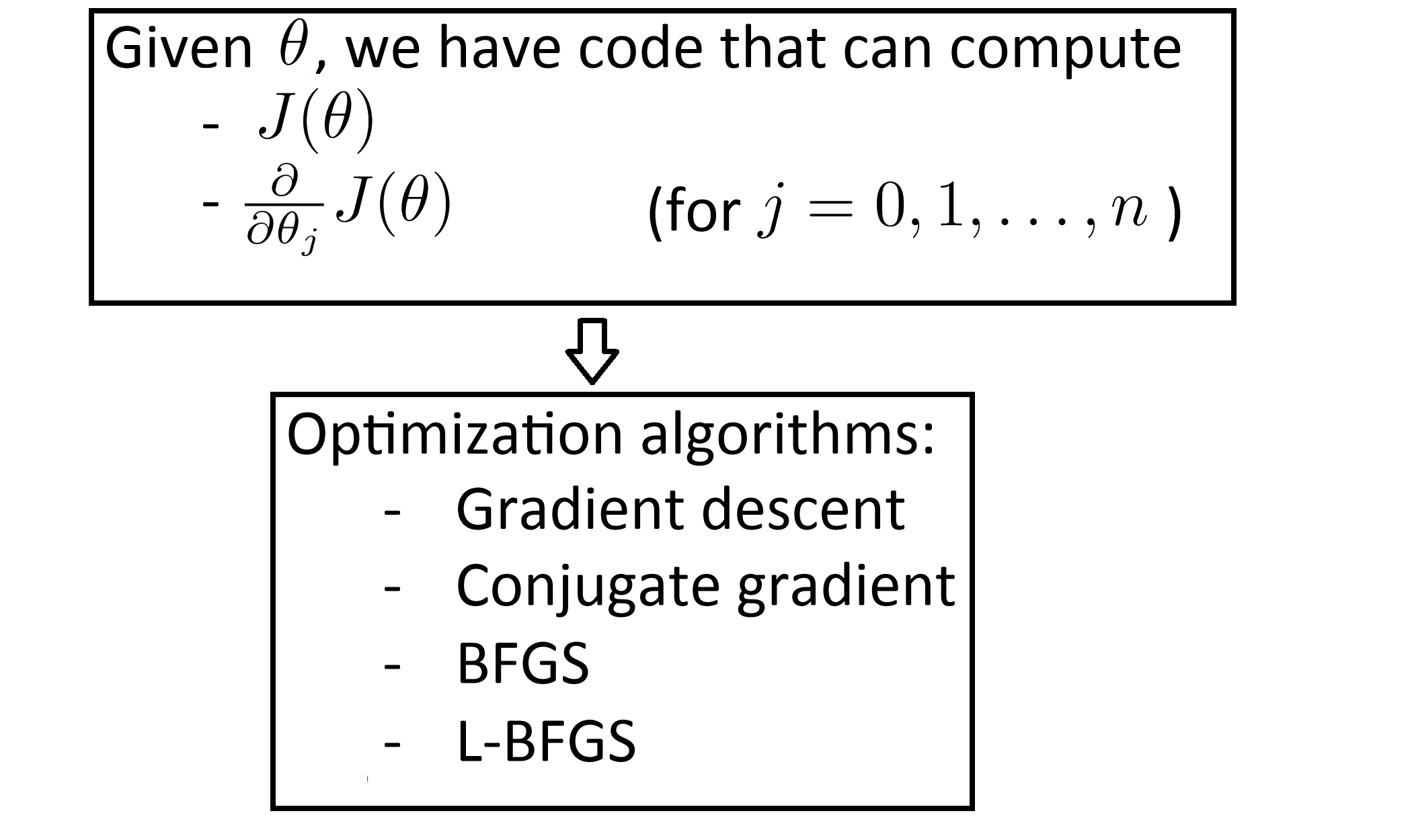
这三种高级算法的具体细节很多,不在这里具体讲解,也许以后会专门写几篇BLOG来讲述这些算法的原理和实现,不过现在我可以告诉你他们的一些特性。这三种算法有许多优点一个是使用这其中任何一个算法我们通常不需要手动选择学习率 α ,事实上他们内部有一个智能的内部循环,被称为线性搜索(line search)算法,它可以自动尝试不同的学习速率 α 并自动选择一个比较理想的学习速率 α ,因此它甚至可以为每次迭代选择不同的学习速率,且它们往往最终 收敛得远远快于梯度下降。
不过关于这些高级的优化算法到底怎么实现的的详细讨论,已经超过了本篇BLOG的范围。但我们实际上完全可以成功使用这些算法(使用现成的算法库)并应用于许多不同的学习,而不需要真正理解 这些算法的内环间在做什么。
如果说这些算法有什么缺点的话,那就是它们比梯度下降复杂多了。所以建议你最好不要手打 L-BGFS BFGS这些算法,除非你是数值计算方面的专家或者码力惊人。就像我不会建议你们自己编写代码来计算数据的平方根或者计算逆矩阵,对于这些算法我,还是会建议直接使用一个算法库,这样运行的效率往往会高不少。
幸运的是,我们有 Octave 和 与它密切相关的 MATLAB 语言,我们可以用到 Octave 中一个很棒的算法的库来实现这些先进的优化算法。所以如果我们直接调用 Octave 自带的库,我们也同样能得到不错的结果。
对于这些算法,实现得好或不好是有很大区别的,因此你在使用C++,JAVA等需要自己加载算法库的语言时,可以在编写前多尝试一些不同的库,以确保能找到一个比较好实现这些算法的库,因为在 L-BFGS 或者其他高线梯度的实现上,写得好与不太好对最后的运行效率会产生很大的影响的。
现在让我们来看看如何在 Octave 中使用这些算法。
优化算法的使用
我们还是通过例子来看看这些优化算法的使用方法。比方说我们有一个含两个参数 θ0 和 θ1 的代价函数,且我们的代价函数 J(θ) = (θ1 - 5)^2 + (θ2 - 5)^2, 因此通过这个代价函数,我们可以得到代价函数 J 的偏导数:
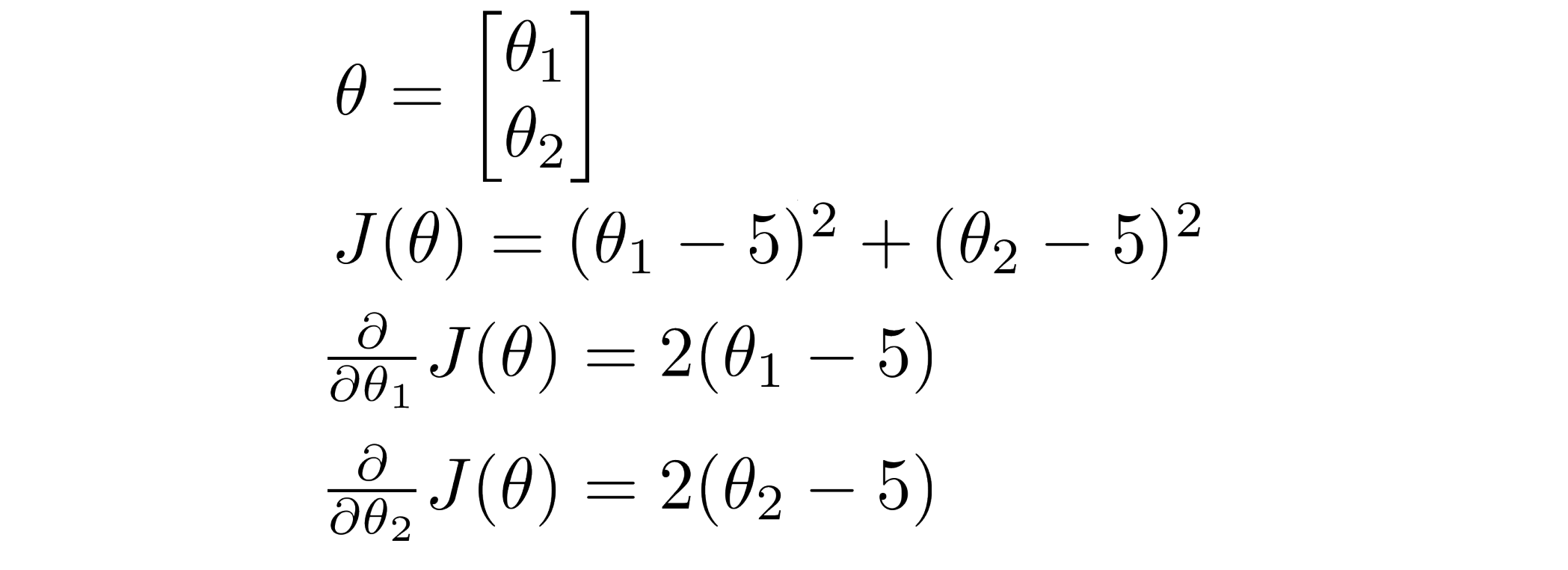
计算出 J(θ) 及其偏导数项后,我们就可以应用高级优化算法里的一个来最小化我们的代价函数 J。在 Octave 中我们可以自行编写函数来计算 J(θ) 及其偏导数项:
function [jVal,gradient]=costFunction(theta)
jVal = (theta(1)-5)^2 + (theta(2)-5)^2;
gradient = zeros(2,1);
gradient(1) = 2*(theta(1)-5);
gradient(2) = 2*(theta(2)-5);这个函数将会返回一个值-J(θ)和一个记录偏导数值的向量。
运行这个 costFunction 函数后,我们就可以调用高级的优化函数 - fminunc 它表示 Octave 里无约束最小化函数,调用它的方式如下:
options = optimset('GradObj', 'on', 'MaxIter', '100');
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options)第一行首先我们要设置几个 options ,这个 options 变量作为一个数据结构可以存储你想要的, 这里的 GradObj 和 On 代表设置梯度目标参数为打开(on),意味着我们现在要给这个算法提供一个迭代次数,然后设置最大迭代次数比方说 100;
然后第二行我们给出了一个 θ 的猜测初始值,它是一个2×1的零向量;
第三行这个命令就调用 fminunc 这个@符号表示指向我们刚刚定义的 costFunction 函数的指针,记得修改文件目录到我们 costFunction 函数目录下!如果你调用 fminunc ,它就会使用众多高级优化算法中的一个,且能自动选择学习速率α,就像加强版的梯度下降法为我们找到最佳的 θ 值。
然后敲击回车键,就得到了最小的 J(θ) 值和对应的 θ :

我们找到了 θ 的最优值,即是 θ1 为5,θ2 也为5,这正是我们希望的 functionVal 的值,而实际上最小的 J(θ) 值是10的-30次幂,基本上可以看成是 0,下面的 exitFlag 为1,这说明它的状态是已经收敛了的。你也可以运行 help fminunc 命令去查阅更多相关资料以理解其作用。
哦对了这里我必须得指出,用 Octave 运行优化算法的时候,向量 θ ,也就是 θ 的参数向量必须是 d 维的,且 d 必须大于等于2,所以若 θ 仅仅是一个实数 fminunc 就可能无法正常运算。因此如果你有一个一维的函数需要优化的话,你可以查找 Octave 里 fminuc 函数的资料来得到具体的方法。
这就是我们如何优化的一个例子,我们优化的是一个简单的二次代价函数。那我们如何把它应用到逻辑回归中呢?

在逻辑回归中我们有一个参数向量 θ ,记住在 Octave 的标号中向量的标号是从1开始的,因此在 Octave 里 θ0实际上 写成 theta(1) ,然后有 theta(2) 一直写到 theta(n+1)。接下来我们需要做的就是写一个costFunction 函数,它为逻辑回归求得代价函数,具体点说 costFunction 函数需要返回 jVal 值,因此我们需要一些代码来计算 J(θ);同时我们也需要给出偏导数值 gradient ,且 gradient(1) 对应用来计算代价函数关于 θ0 的偏导数,接下去关于 θ1 的偏导数依此类推。再次强调这是 gradient(1) gradient(2) 等等,而不是gradient(0) gradient(1),因为 Octave 的标号是从1开始而不是从0开始的。总而言之我们需要写写一个函数,它能返回代价函数值以及偏导数值,接下来就可以把这个应用到逻辑回归或者甚至线性回归中。我们也可以把这些优化算法用于线性回归,我们需要做的就是输入合适的代码来计算上图中的那些东西。
现在你已经知道如何使用这些高级的优化算法,有了这些算法,我们就可以使用一个复杂的优化库来计算庞大的机器学习问题。
结语
通过这篇BLOG,相信你已经了解了一些梯度下降的高级优化算法以及具体的使用方式,快去实践看看吧。最后希望你喜欢这篇BLOG!

